
这是一个对Speaker-Recognition(SRE)任务进行简单介绍的文章。介绍了SRE任务的一些子任务和常用的评测标准以及常用的方法。
说话人识别概念
Speaker-Recognition,即说话人识别。根据任务目标不同,说话人识别可以分为说话人确认(Speaker Verifica-
tion)和说话人辨认 (Speaker Identification) 两大类。说话人确认是判断某段语音是否为指定的说话人所说(Yes or No),是一对一的判别问题;而说话人确认则是对于众多候选说话人集合,给定一段语音,确定该段语音是候选人集合中的哪一个人所说,是多对一问题。说话人识别基本的框架如下:
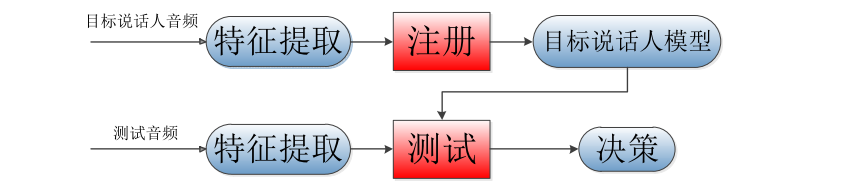
根据注册阶段和测试阶段的语音的文本内容是否一致,说话人识别可分为与文本相关(text-dependent)的说话人识别和与文本无关(text-independent) 的说话人识别。前者要求注册和测试语音不仅来自同一个人所说,而且说话内容一致,一般用于使用者比较配合的场合,在此种情况下不用担心说话内容的 差异带来的困难因而识别性能更好;而后者对说话内容不作限制,因而使用起 来更加灵活自由,也不易被非法模仿,但是识别起来技术难度增大,性能不如前者好。
说话人识别任务的评价指标
对于说话人辨认任务来说,我们可以简单的用正确率进行评价。
在说话人确认任务中,先给出两个重要的概念:
- 错误拒绝(False Rejection, FR):正确的说话人在测试中被断定为冒认者
- 错误接受 (False Acceptance, FA):冒认者在测试中被认为是正确的说话人
由于存在错误拒绝和错误接受两类错误,单纯地使用错误率来评定说话人确认系统性能可能是不恰当的。
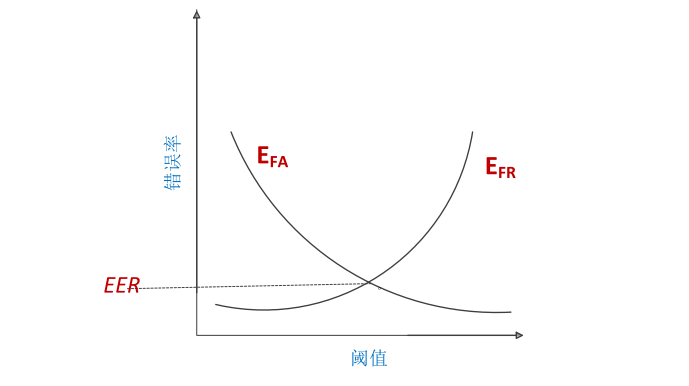
等错误率(Equal Error Rate, EER):
首先我们定义错误拒绝率$E_{FR}$和$E_{FA}$:
$N_{fr}$和$N_{fa}$分别是测试中错误拒绝和错误接受的次数,$N_{target}$和$N_{imposter}$分别指测试中总的真实测试次数和冒认测试次数。当系统中的阈值一定,$E_{FR}$和$E_{FA}$便是一定的,当阈值降低时,会有更多的测试会被接受,此时$E_{FA}$增大,$E_{FR}$减小,反之亦然。如下图是$E_{FR}$和$E_{FA}$随阈值变化而变化的趋势,EER为当$E_{FR}$和$E_{FA}$相等的时候的错误率。
DET(Detection Error Trade-off) 曲线:
传统方法
- 基于GMM-UBM系统的说话人确认系统