
这是一片对于论文X-VECTORS的阅读笔记,虽然NLP和CV领域的全部江山几乎已经被深度学习占据,而在SRE领域传统方法仍有这一定的地位,我认为这篇文章是深度神经网络在SRE领域的一个很好的应用。
近些年来,在说话人领域越来越多的文章提到embedding这个词。用深度学习网络所提取的说话人embedding与之前的说话人i-vector是一样的。都希望将说话人通过映射到一个向量空间,在这个空间里,同一个说话人的speech映射得到的embedding距离会比较近,而不同说话人的speech映射得到的embedding距离尽可能远,也就是说我们希望这些特征更加的可区分。在这篇文章中,作者使用TDNN和statistic pooling这两种结构将变长的语音特征输入转化为了定长的embedding。
x-vector这篇文章其实是David Snyder等人在他们之前的工作 ‘’Deep Neural Network Embeddings for Text-Independent Speaker Verificatio‘’ 基础上所做的进一步工作,在这里,我们把这两篇文章都说一下。在一下的文章中我们简称之前的那篇文章问x-vector1,题目所给的这篇文章为x-vector2。
Introduction
在x-vector1中作者提出,已经有人在大数据上利用深度神经网络取得了很好的效果(这一点也与数据量对深度学习的影响很大这个观点很符合),但这些大型的数据一般都是公司私自的数据,所以x-vector1可以说是一次在已有公共数据集上的说话人文本无关任务的探索。而且对于实际情况的考虑,由于延迟或者为了进行说话人的实时验证,测试时能够使用的说话人音频长度是有限的,所以在这两篇论文中都对于不同的长度的test segment的语音进行了测试。此外,根据之前的诸多研究发现,embedding比i-vector能够更好的利用大量的数据,在x-vector2中作者还探索了数据增广对于系统的作用。
Baseline system
- 以20维mfcc特征加delta和delta-delta之后组成的60维特征为输入的i-vector系统
- 以20维mfcc特征加delta再加上在Fisher English corpus上训练的60维bottleneck特征组成的100维特征作为输入的i-vector系统(只在xvector2中有)
xvector系统结构
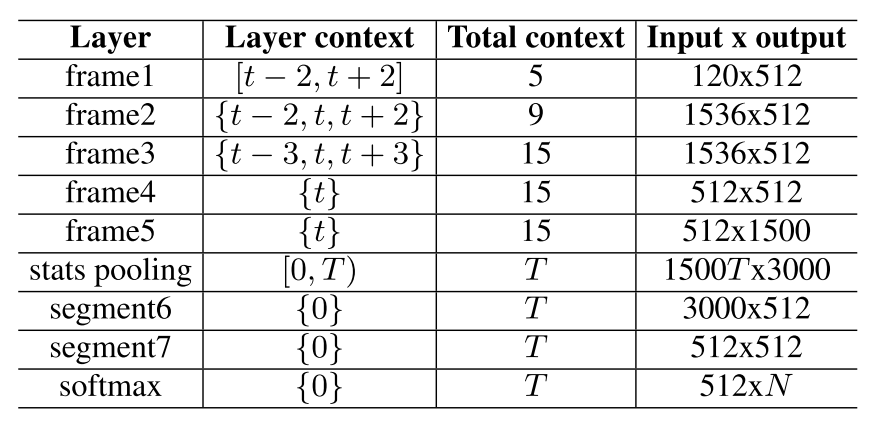
- 第一层相当于splice 5 (每一帧拼接前后两帧)之后作为输入。这里用TDNN来实现
- 第二层也是用TDNN来实现,只不过这里拼接的不是连续的几帧,而是相隔的。这样做是为了减少重复运算,因为有些帧对应的context是重叠的。这种拼接的方式就是为了让拼接起来的每一帧的context没有重叠。
- 这样以来,到了四五层的时候每1帧的实际上下文是15帧.
- 由于语音通常不具有相同的输入长度,所以stats pooling用于计算所有输入帧的均值和方差,并将这两个统计量拼接起来作为之后的输入。
- 最后可以将segment6或segment7作为最后说话人对应的embedding
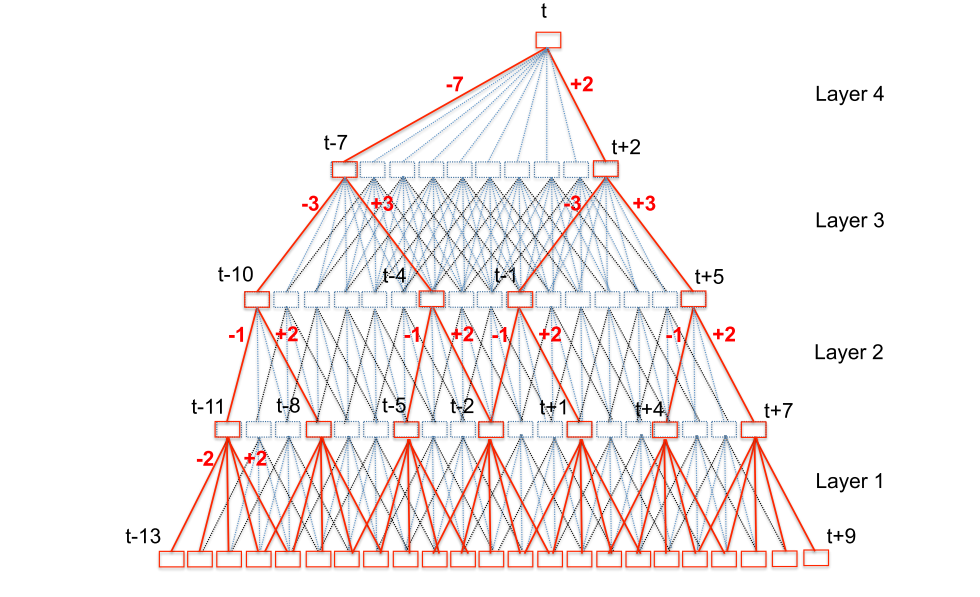
TDNN结构图(x-vector所用的参数和这个图略有不同):
打分策略
这里的x-vector系统和i-vector是一样的,只做说话人级别的特征提取。最后我们使用LDA对特征进行降维在用PLDA进行打分。
实验
- xvector1
- 训练集(i-vector和xvector):部分SWBD以及SRE2004-2006
- 训练集(PLDA-based backends):只用SRE
- 验证集:SRE10和SRE16(非英语),其中SRE16的enroll speech是60s,test speech在10s到60s之间分布。SRE分两种情况:
- enroll 和 test都是10s(在图表中的标记是10s-10s)
- enroll是full length,test的长度属于{5, 10, 20, 60}
- 网络的segment6或segment7都可以作为embedding,分别记为embedding a和embedding b
- 所有实验的融合(fusion)方式都是score 的平均
- xvector2
- 训练集(i-vector和xvector):部分SWBD以及SRE2004-2010和Mixer 6
- 训练集(PLDA-based backends):只用SRE和Mixer 6
- 验证集:SITW和SRE16的Cantonese部分
- SITW:英语说话者、entoll和test:6–240 seconds
- SRE16:粤语、enroll:60s test:10–60s
- xvector将segment6作为embedding
- 相较于xvector1,xvector2还做了data augmentation的实验。分别或者同时对extractor(UBM/T or embedding DNN)和 PLDA classifier做data augmentation
实验结果
xvector1
SRE10上的结果
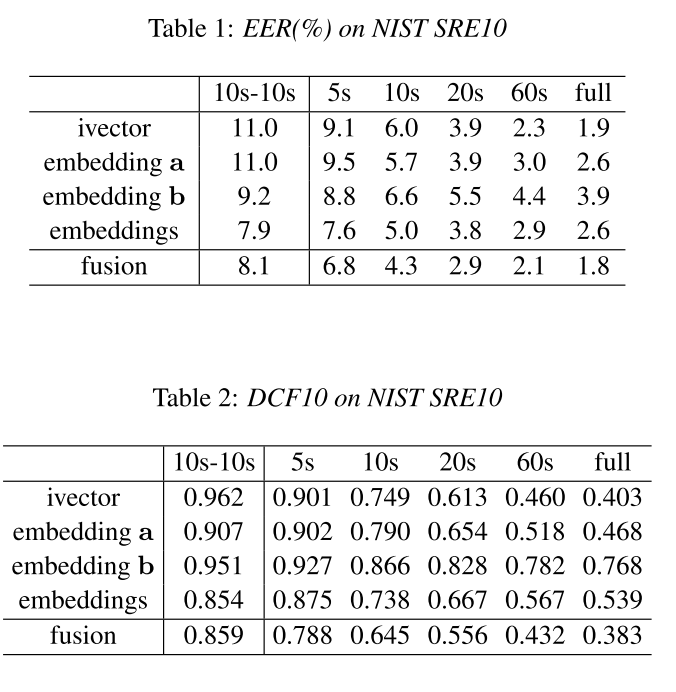
从SRE10上的结果可以看出,i-vector在长时间的test集上的性能仍然是很好的,比embedding还要好一些。而当test所用的语音时长变短的时候embedding变得越来越好。而且embedding和i-vector是互补的,当两者进行fusion的时候,结果会变得更好。
SRE16上的结果
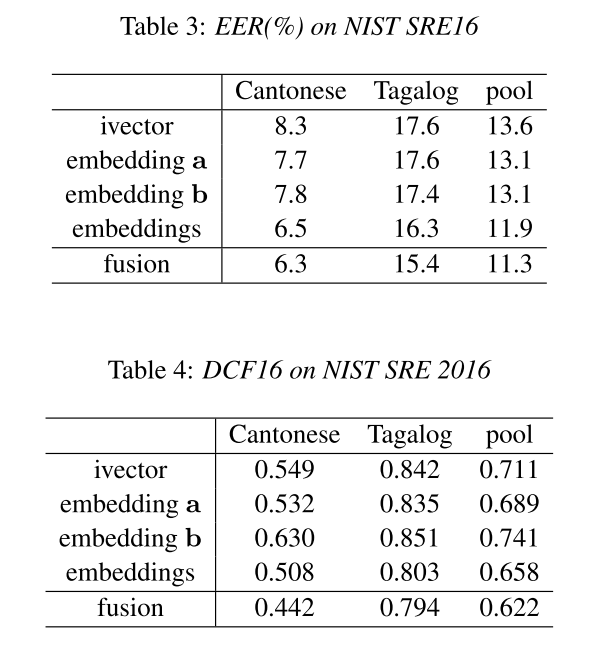
从上面的结果可以看出,embedding在跨语言方面的有着更大的优势。
xvector2
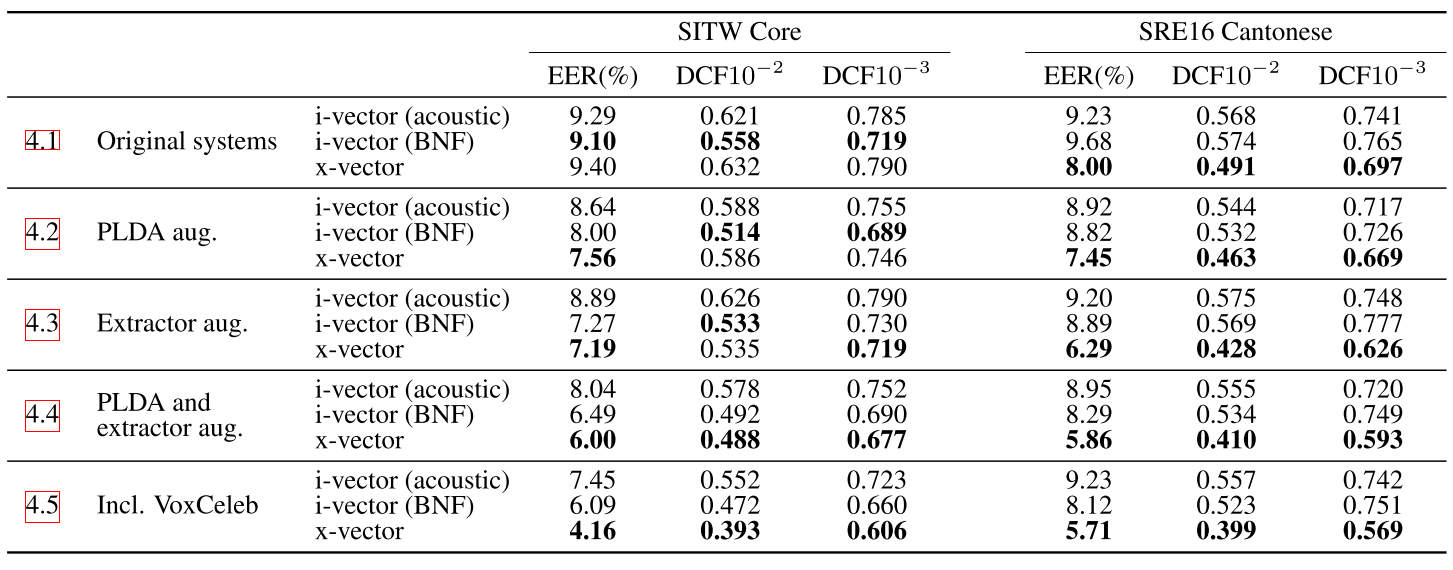
第一栏
- 没有经过数据增广的训练,i-vector(BNF)在SITW上表现良好
- 但是经英语数据集训练的i-vector(BNF)无法在非英语数据集上取的良好的表现
第二栏
对于PLDA训练数据的增广,对于实验有着很大的帮助
第三栏
- 对于i-vector系统的数据增广训练没有对系统有帮助
- 对于x-vector系统的数据增广训练带来的提升超过了plda部分的数据增广训练
- 数据增广似乎只对有监督的训练有效
第四栏
对PLDA和extractor系统都做数据增广,x-vector系统的性能提升很大
实验结论
xvector1
xvector能更好的对于短语音建模
关于原因,我是这样理解的。之前有篇文章提到过i-vector系统的duration-mismatch。也就是说,如果训练i-vector系统的时候用的是长语音,而提取的时候用的是短语音,就会产生mismatch。原因是这样的,UBM和i-vector可以看成是对音素建模的,每个UBM的高斯可以看成是一种音素的分布(当然毕竟不是有监督训练,我们只能这样看,严谨的来说这样是不准确的)。语音过于短的话相应的音素可能就没有被包含,那么i-vector中对这个音素进行表达的相应维度的值就会很小。实验也证实了短语音的i-vector的模长会更小。
xvector对于domain mismatch更加鲁棒(跨语言)
我对于这个原因的理解同上面。i-vector对于音素建模,不同语言的音素会有差异,可能会导致i-vector的性能不佳。
最后作者认为,PLDA对于embedding来说应该不是一个好的度量方式(个人理解是,PLDA有着高斯分布的假设,而embedding的分布不一定是高斯的)。作者希望能够用一个end-end的结构对最后的结果进行评判。
xvector2
- 数据增广的方法似乎只对有监督的方法有效,对于i-vector系统的帮助并不是很大。
- BNF特征对于i-vector的系统帮助是很大的,但是相对于传统i-vector,加入BNF之后计算复杂度会增大很多。而且BNF对于数据有着比较严格的要求,需要数据有转录的文本。而且BNF在domain之间的适应性不是很好,需要大量的in-domain数据进行训练
- 相较于BNF,x-vector只需要有说话人标注的数据即可,而且数据增广对于xvector系统的提升有着很大的帮助。