
TDNN在序列建模领域好像已经出现很久了,但自己之前一直没有了解,这篇博文只对文中TDNN的部分做以记录和理解,全文的内容还请移步原文。
前言
对于序列输入,学习序列前后依赖性是很重要的。RNN系列的模型能够很好的对于序列进行建模,但由于RNN的序列输入的本质,使得对于RNN的加速(主要是并行加速)相对于普通的DNN变得很难,因此RNN的训练时长很长。而time delay neural network(TDNN)的出现就是为了折中进行序列建模和训练时间短这两个目标。
Introduction
这篇文章所介绍的TDNN结构是在之前提出的TDNN结构上的一种改进,虽然TDNN是一种前向网络的架构,但是如果在所有的time steps上计算隐层的激活计算量仍然是很大的。在本文中,作者采用了一种subsampling的方式,只对某些time step进行计算,这中subsampling是建立在所有的输入上下文都会被网络处理的基础上的。
相较于RNN,TDNN does not impose any relationship between the length of input-context (i.e., unfolding width used during training, in case of RNNs) and number sequential steps during training. 自己虽然之前了解过RNN和lstm,但现在有些记忆模糊了,等再做了解之后再对这句话做诠释和理解。
TDNN Neural network architecture
对于一般的DNN在处理上下文时,想法一般是这样的。比如我们想提取具有上下文分别7帧共15帧的特征表达,我们一般会将这15帧的特征直接拼起来,形成一个15*F(F是我们每一帧的特征维度)的特征,然后去学习15*F的特征映射。
而对于TDNN来说不是这样做的,假如我们最后仍然想获取时序上15帧上下文的特征表达。在TDNN的初始层中,会处理比15帧更加窄的时序上下文,然后送入更深的网络。很容易理解,更深的网络的时间分辨率是比底层网络要长的。也就是说,我们将“获取时序上15帧上下文的特征”这个目标交给了更深的网络去完成,而不是用一层网络来完成。 如下图,最下面一层的时间分辨率为5,而最上层的时间分别率是23.
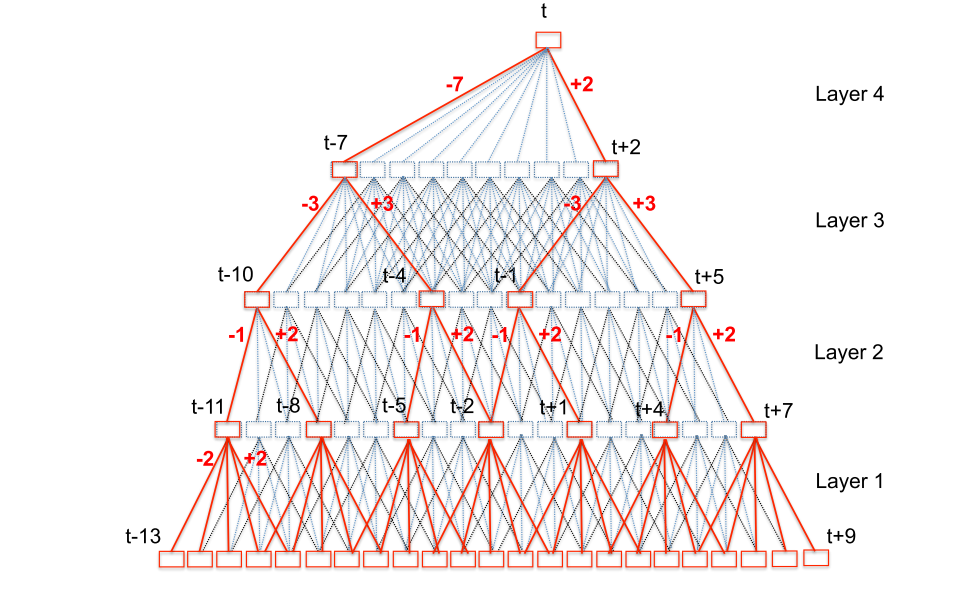
此外,TDNN在同一层,不同time steps上的这个transform参数都是共享的(类似于CNN中的卷积核在整张map上的参数共享)。所以对于TDNN来说,其中的一个超参数就是每一层的input context。
TDNN subsampling
从上图可以看出,TDNN临近time step的特征(非输入层)是有很大的context重叠的。假定这些相邻的time step特征之间是相关的,我们在进行特征拼接输入下一层的时候是不必拼接紧挨着的time step的。也就是说我们可以隔几个time step进行拼接。这些做的话,如上图,红线所示的路径就是我们最后需要计算的部分。
此外在这个文章的TDNN的结构中,用的是非对称的上下文,也就是说当前帧之前取13帧,当前帧之后取9帧,这可以降低实时解码的延迟(减少对于未来帧的使用)