
最近想复现这篇论文,顺便把论文阅读笔记和复习的新的记录一下
前言
这篇文章是google发的,是在其之前的tuple loss的基础上进行的改进。实现了EER的降低和训练的提速。而且在这篇文章中,还提出了一个MultiReader的概念,使得可以使用domain之外的数据进行训练,从而得到一个更加准确的模型。
Introduction
本文所设计的说话人验证包括文本无关的说话人任务和文本相关的说话人任务。
Tuple-Based End-to-End Loss
每次训练的一个step输入是一个eval 的特征Xj~和M个注册特诊Xkm(m=1,….M)j和k代表这些特征的说话人。输出是这些特征的embedding,而且每个embedding被L2方式normalize,这些处理之后的embedding记为{ej~,(ek1,…,ekM)}. 如果j=k,我们乘这个tuple为positive的,否则为negative的。M个utterance的embedding的中心计算如下:
相似度度量方式为(w和b是用来学习的参数):
最后的TE2E的loss定义为:
sigma函数就是机器学习中常用的sigma函数,delta函数的定义是如果j=k函数值就为1,否则就为0.
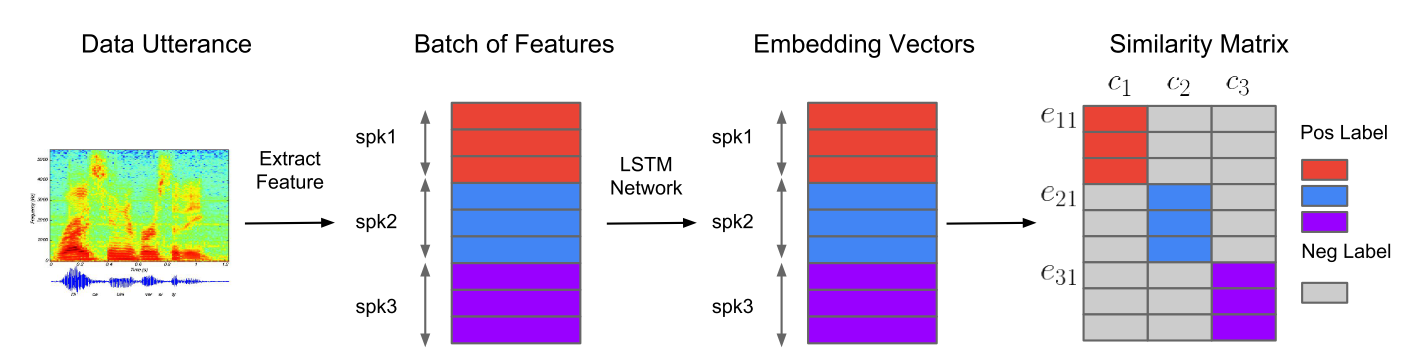
GENERALIZED END-TO-END MODEL
相对于上文提到的tuple loss,generalized end-to-end在模型的输入上做了改变。输入是NxM个utterance。N是指N个说话人,M是每个说话人的utterance的个数。将这些输入作为一个batch输入。
定义输出结果的相似矩阵:
相对与TE2E中的相似度定义,这里的相似度是一个矩阵,每个说话人计算一个中心,每个utterance的embedding都要计算和这个中心的相似度。而TE2E中的相似度就是一个值。
Training with MultiReader
作者在这篇文章中想解决in-domain数据比较少的问题,而且可以防止模型在较少的in-domain数据上过拟合。可以用out-domain 的数据和in-domain的数据一起训练。比如存在两个domain的数据D1和D2,那么最后的loss定义就是:
相当于为两个数据集的loss赋予不同的权重,以代表其在训练中的重要性(当然不一定只用一个out-domain的数集,也可以是多个)。训练过程是这样的,在每一个训练step,分别从每一个D中抽取一个batch,并获得相应的loss。
论文复现心得
lstm确实有点难训练
- lstm收敛很慢,自己把提特征的lstm换为TDNN之后很快就训练结束了
- 如果lstm的输入序列太长,lstm几乎不收敛,因为在梯度反传越来越小,太长根本传不动。而且自己这个任务无法使用截断的BPTT,因为并不是每一个时间step都有loss,只在最后的输出才计算loss(头疼啊)。但是TDNN在加长了序列之后完全没问题,收敛速度甚至提升。当然,之前看cs231n的课程的时候,说在用lstm的时候,通常用特定的初始化,使得forget gate值的输出为1,这样在刚开始训练的时候收敛会加速,之后自己试一下吧。
python进程似乎不是越多越好
因为读数据太慢,自己开了好多个进程读数据,用queue保存。但发现数据load进程太多了之后,主进程似乎和数据load进行是串行的了(之后发现应该是自己申请的cpu核并没有自己开的进程多,所以并行就变串行了)。
相似度矩阵乘w加b,进行放缩的作用
自己刚开始从理论上分析,这个东西应该没有任何作用。因为所有的得分都做了同样的放缩,得分的相对大小并不会有变化。但有次跑实验的时候,自己忘了加这个操作了,结果发现训练巨慢。我觉得原因应该是这样的:在embedding算loss之前,做了l2 norm,也就是除了一个大于1的值,也就会导致loss反传的时候会乘一个小于1的值,导致梯度减小,收敛减慢。而这个放缩,会使减小了的梯度变大,从而收敛加速。(为什么这样分析呢?因为自己如果不做l2 norm也不做这个w、b的放缩的话,收敛速度也很快)。总之,训练真的有很多细节吧。