
最近因为要使用LSTM,所以就临时学了下RNN、LSTM和GRU以及LSTM和GRU的初始化问题,并在这里总结一下。
RNN
What is RNN
RNN是Recurrent Neural Network的缩写,即循环神经网络。
Why RNN
为什么要使用RNN,就像世界上的每一件事情的发生都是有原因的。每一个结果都是一步一步随时间演进出来的,我们如果想要推断出最后的结果,就需要之前各个时间点的知识,这就是RNN出现的原因。RNN的输入是一个有序的序列所有这些序列通过RNN最后得出RNN的输出。
How RNN
那么怎么实现RNN呢?
RNN前向传播
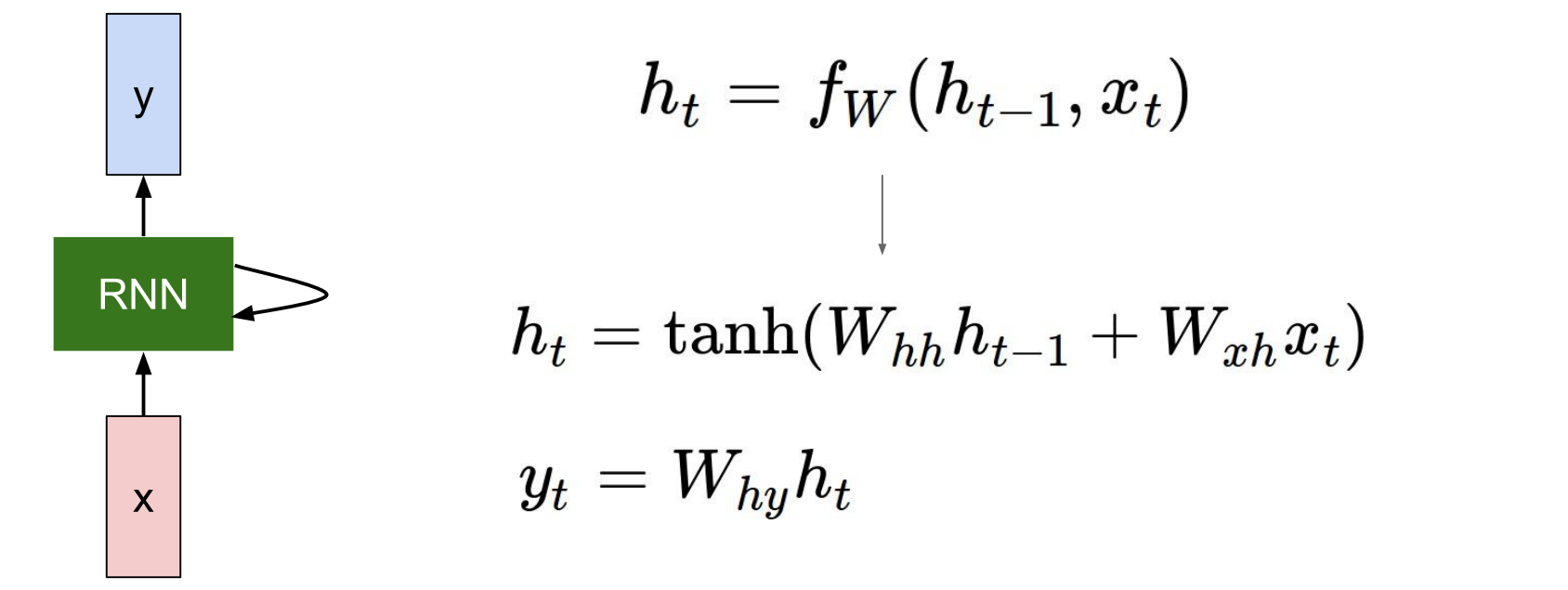
上图是RNN的基本结构,RNN每个时间step所对应的网络结构都是一样的。RNN的每一个时间step都有两个输入。一个是当前时间的输入$x_t$, 还有上一个时间的hidden state记为$h_{t-1}$ .这两个输入通过矩阵运算再通过某种非线性函数可以得到当前时刻的$h_{t}$。当然对于不同的任务,可能在每个时间step上还会有一个输出y。如果我们将左图按照时间展开,就会得到下图:
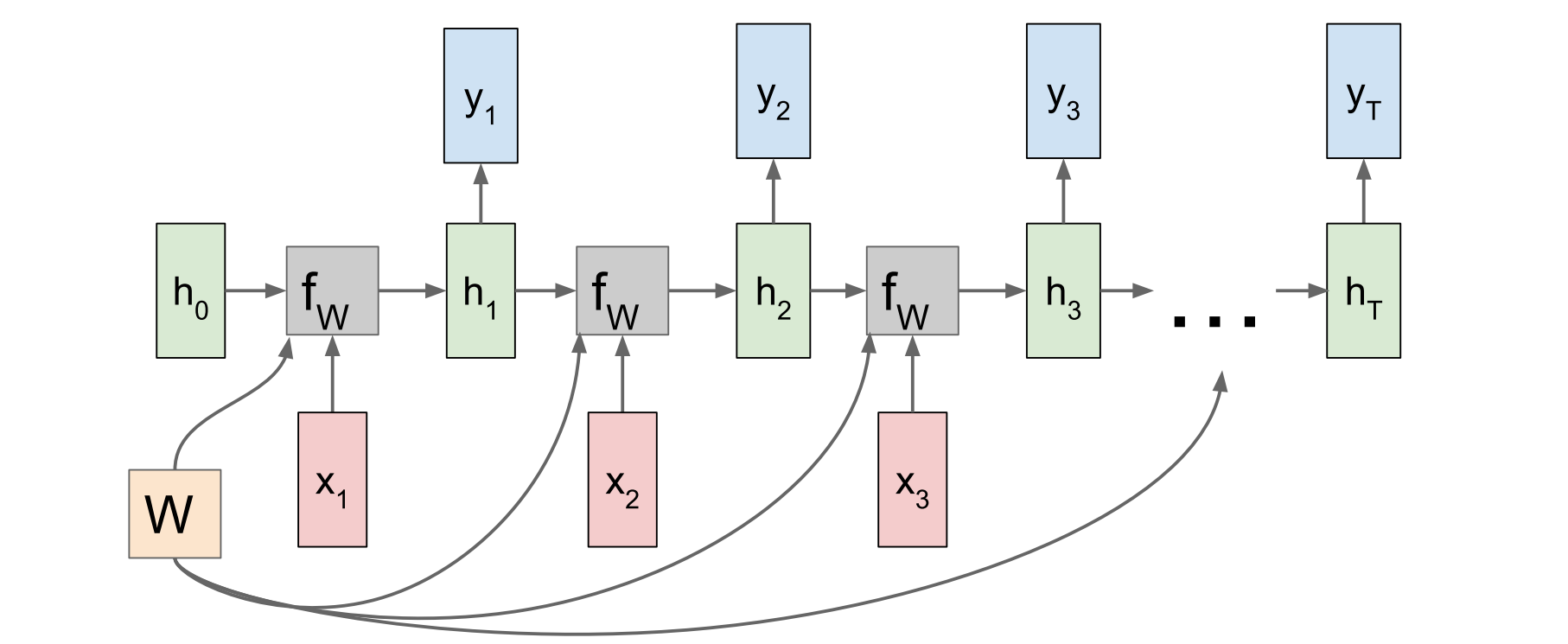
上图中W所指示的曲线表示,所有的time step中用于计算$h_{t}$的权重是共享的。
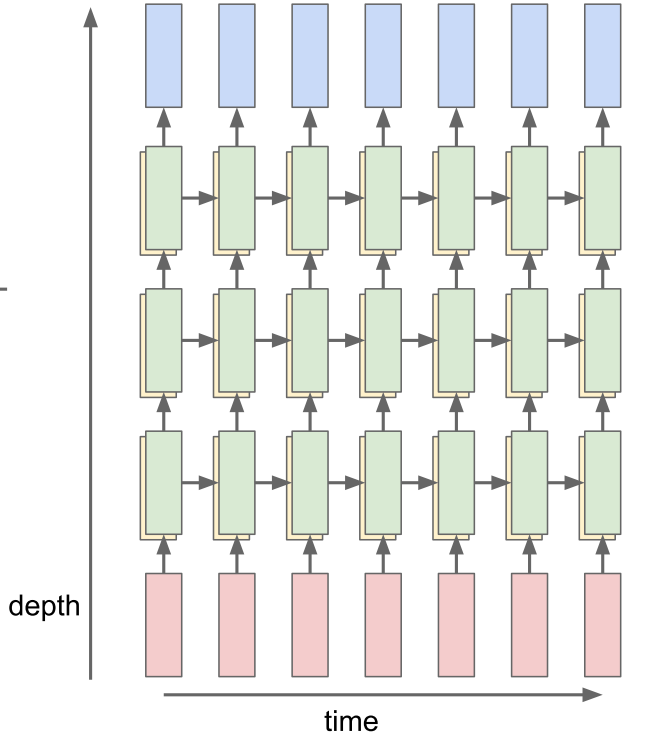
当然,和普通的神经网络一样,RNN不仅可以在时间维度上进行延伸,也可以做网络的堆叠,即构造更深层的网络,网络越深,网络的学习能力肯定也会有提升,但RNN一般不用特别深的网路,一般常用的layer个数是二、三、四。如下图。
Backpropagation through time
RNN所用的反向传播算法,有一个专门的命名,叫做Backpropagation through time(BPTT)。
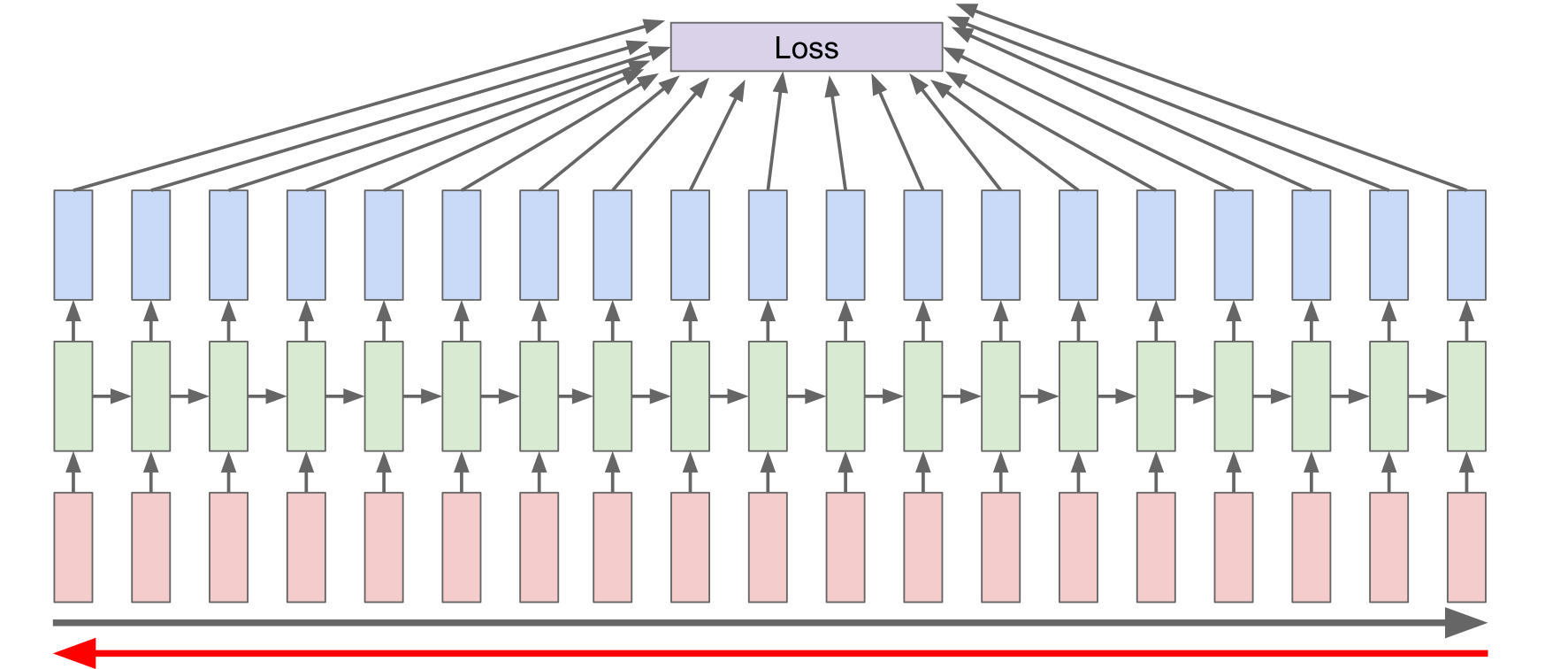
每个时间节点的输出都可以计算出一个loss,最后将这些loss求和,进行回传。那么为什么叫做through time呢?很容易想,因为计算图是在时间维度不断往后延伸的,那么某个time step的输出所算出的loss肯定要不断向前回传直至时间的起点。就如下图所示:

BPTT会产生的问题
我们从上图可以看出,沿时间的回传每次经过一个time step的内部就会乘以一次W。如果我们把W当成实数来看,如果W<1,那么多个w连乘梯度会越来越小,从而出现vanishing gradients(梯度消失)的问题、如果w>1,那么多个W连乘梯度会越来越大,从而出现Exploding gradients(梯度爆炸)的问题。
Exploding gradients(梯度爆炸)问题的解决
对于梯度爆炸,我们一般会采用Gradient clipping的方式将梯度限制在某个范围里:
1
2
3grad_norm = np.sum(grad*grad)
if grad_norm > threshold:
grad *= (threshold / grad_norm)当然,梯度爆炸也可以用之后的LSTM得到一定的缓和。
Truncated Backpropagation through time
真正在实际应用的时候,并不会像上面所提到的那样直接进行梯度回传。假如我们的序列输入很长,那样回传的话会面临几个问题:
- 沿时间回传梯度逐渐变小,几乎为0,越往前越没有意义
- 序列过长,模型需要经过很长的前向之后才能跟新,模型更新速度慢
所以,新的反向传播方式被提出:
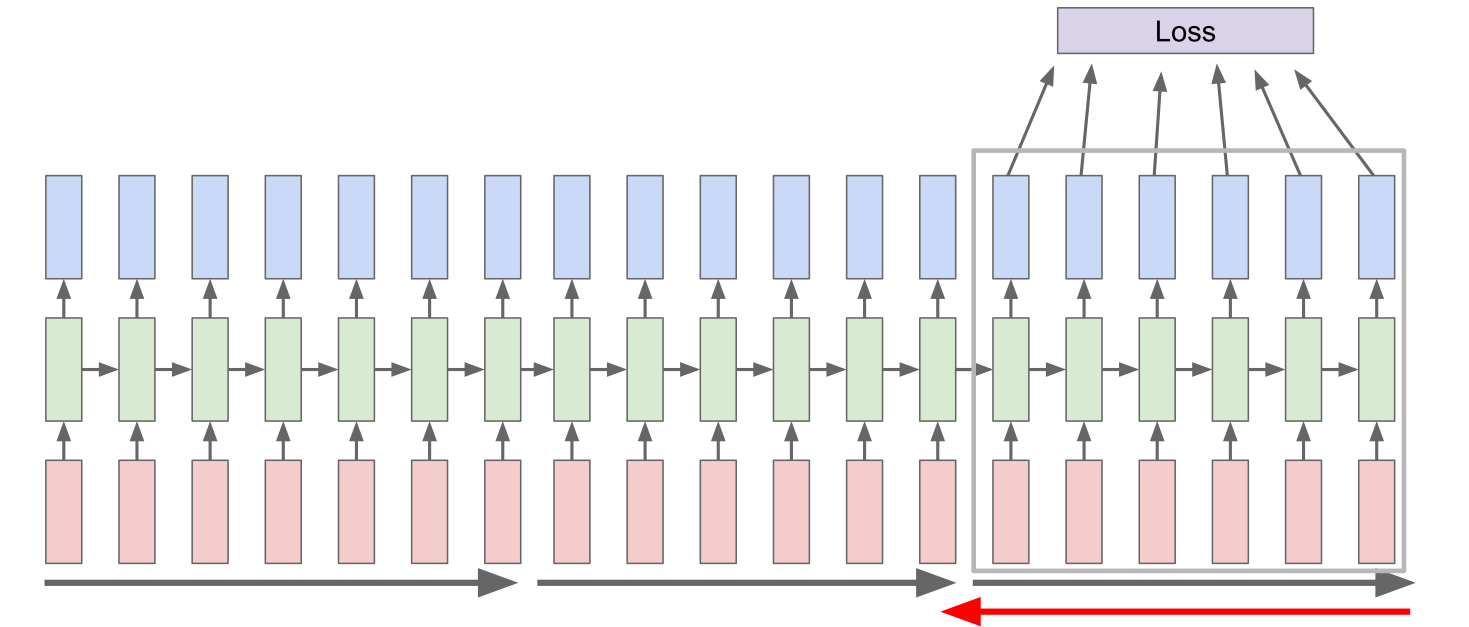
被称为是截断的BPTT,也就是我们不回传的序列的起点,而是只在某个固定的时间长度上回传,如上图。具体的实现细节是这样的。
在进行算法实现的时候,我们会指定两个参数,$k_1$和$k_2$。算法的伪码如下:
1
2
3
4
5
6for t from 1 to T do
Run the RNN for one step,compute loss each step
if t divides k1 then
Run BPTT, from t down to t − k2
end if
end for也就是说我们的序列长为T,我们不断进行RNN的forward计算,但是每隔$k_1$个step,我们会对参数进行一次更新,每次更新需要使用BPTT的方式,BPTT的计算被限制在当前更新step之前的$k_2$个step。
LSTM
从上面总结可以看出,普通的RNN还是有很多的缺点的。于是人们又提出了LSTM这种改进版的RNN结构。说起LSTM,就必须祭出下面这张非常非常经典的图。
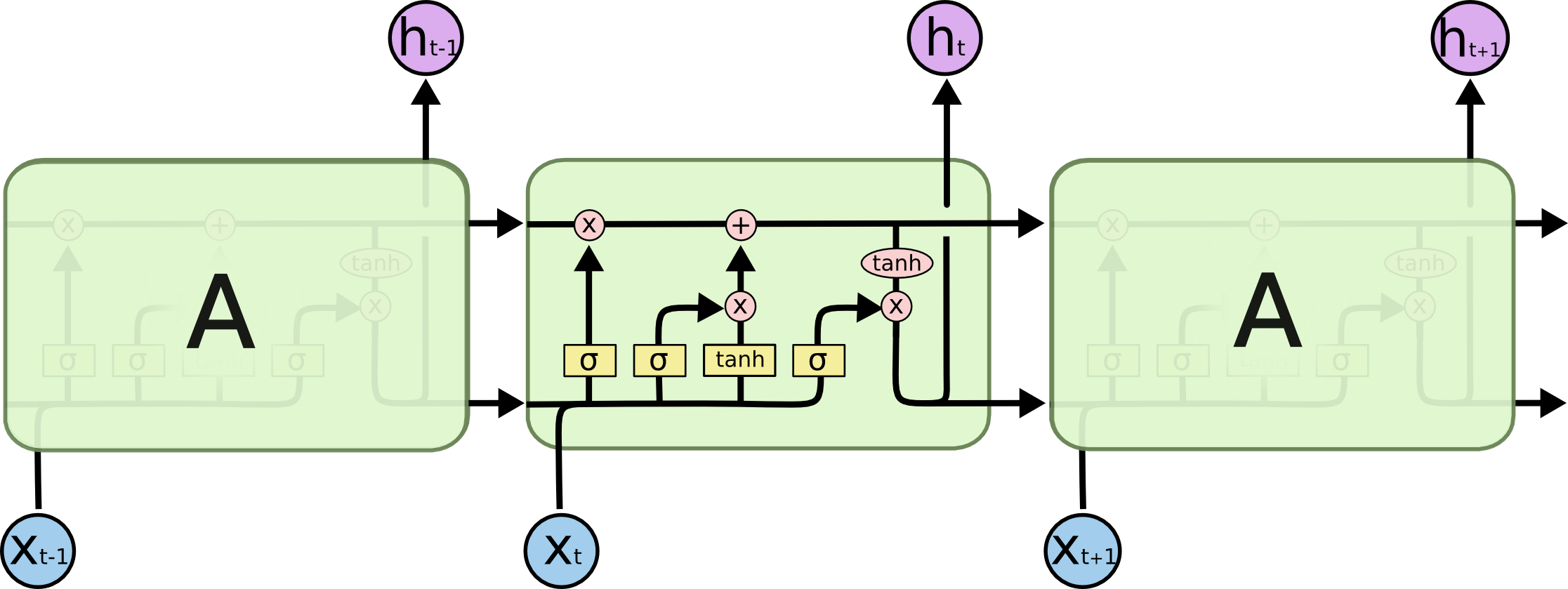
从宏观上看,LSTM和普通的RNN没有什么区别,都有$x_t$和$h_t$。不同的就是$h_t$的计算方式和每个RNN的block多了一个输入和输出。下面是LSTM关于$h_t$的计算方式:
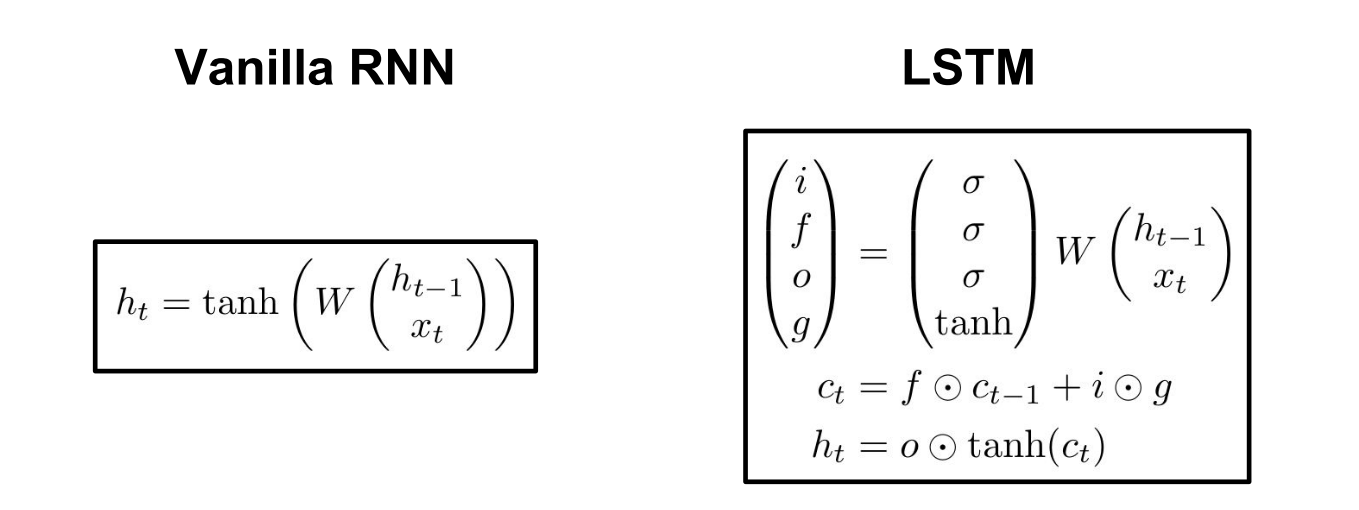
相比于普通的RNN,LSTM多了个$c_t$, 被称之为cell state。f代表的是forget gate(遗忘门),i代表的是input,o代表的是output,g呢,没有特定的名称。i,f,o,g四个向量的维度都是一样的。
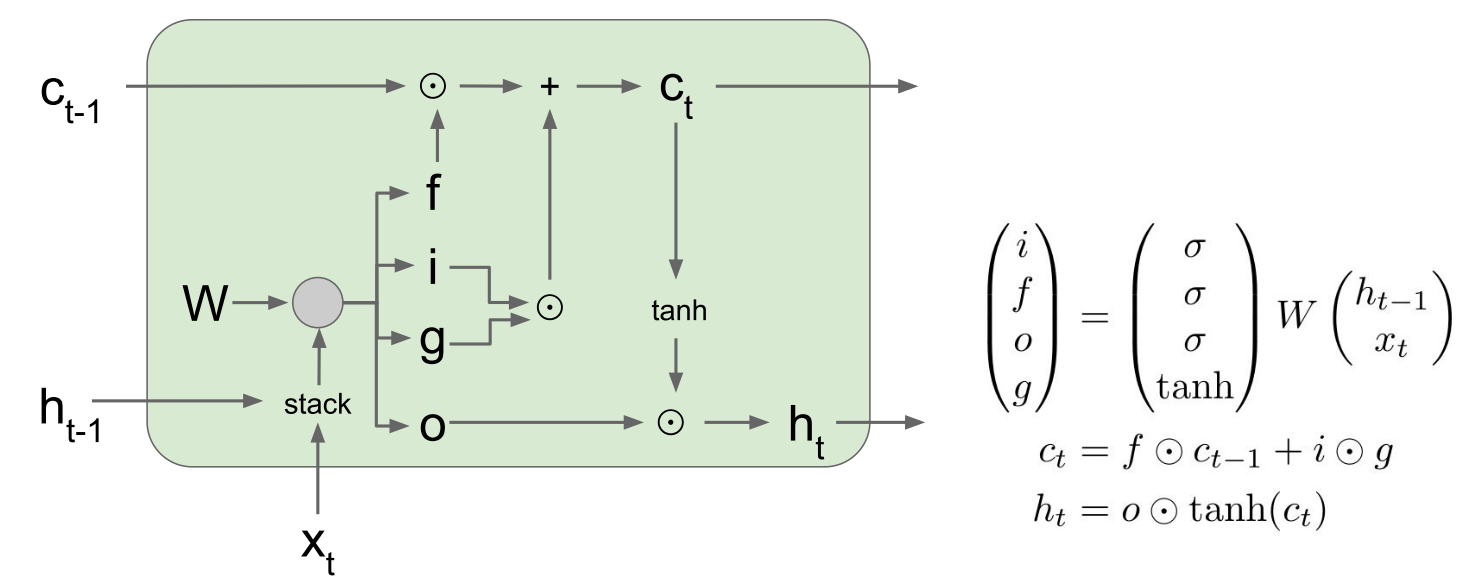
从图示中我们可以这样理解:
- 首先,$x_t$和$h_{t-1}$拼在一起通过矩阵运算计算出四个维度一样的向量f,i,g,o。
- 然后f因为是通过了sigmoid的所以取值是0-1.上一个step 的$c_{t-1}$通过和取值位于0-1的f点乘获取输出,遗忘门的意思就是我们要对上一个step 的$c_{t-1}$遗忘多少,然后将剩下的传给下一个step。
- 然后i和g点乘加上上一个step被遗忘部分后剩余的$c_{t-1}$变成当前step的 $c_{t}$。
- o作为$h_t$输出。
Why LSTM is better
普通的RNN在进行BPTT的时候要不断乘以W,可能会导致梯度消失或爆炸。
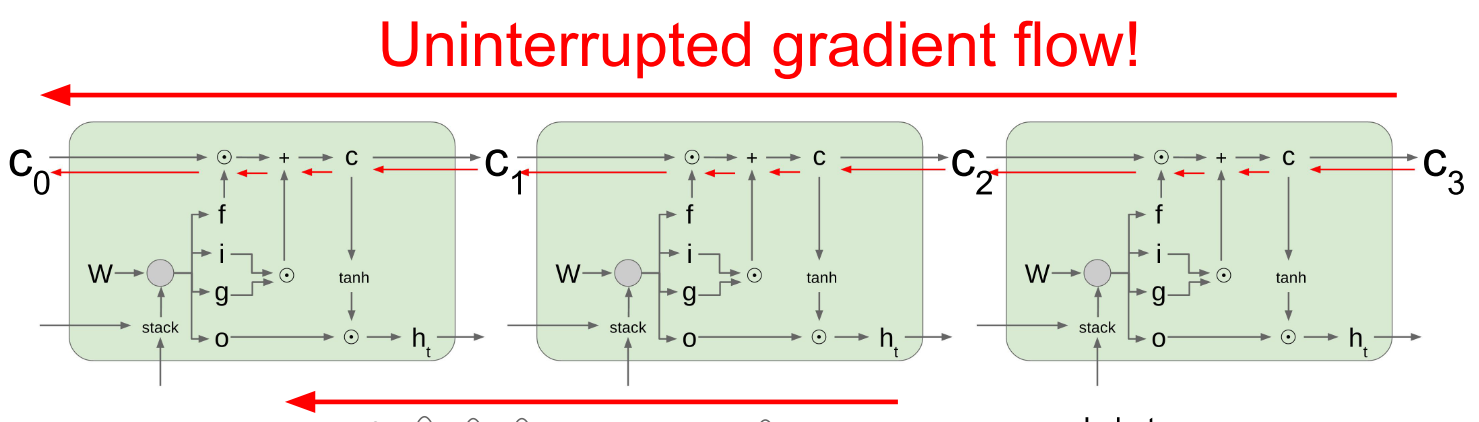
但是LSTM在梯度回传的时候除了经过W的那条路之外,还有另外一条路,就是上图细红箭头所示的flow。在这条路上进行回传,梯度的大小就主要取决于f的值了。f对于每个step来说不是常数,效果会比普通的RNN好些。当然f是一个0-1的值,梯度也会不断减小,一般来说,在训练的时候会通过某种初始化是f一开始比较接近于1,这样会加快训练速度。
LSTM这种梯度回传的策略其实很像CNN中的resnet。
GRU
GRU是在14年被提出来的,相当于是LSTM的一个变种。
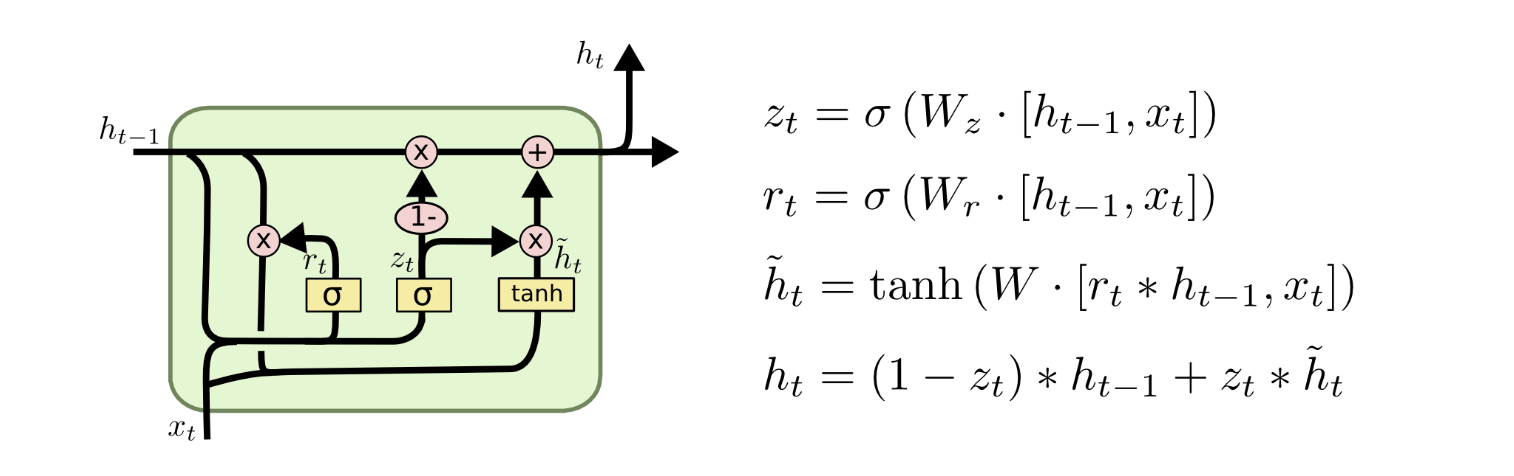
相对于LSTM,每个GRU cell只保留一个状态,那就是 $h_t$,不再有LSTM中的 $c_t$。这使得GRU相对于LSTM会简单一些,和LSTM相似,最后的公式中,直接将 $h_{t-1}$ 作为一项求和可以为反向提供高速公路以减小梯度消失的影响。
关于RNN训练的tips
不管是传统的RNN还是LSTM或者是GRU都比较难以训练,虽然LSTM和GRU在减缓梯度消失方面多做了一些,但是这并不能完全避免梯度的消失。
所以LSTM和GRU的初始化问题都是很重要的。这个初始化也都是针对梯度消失的,为了防止刚开始训练时候的梯度消失,我们会使LSTM中的 $c_{t-1}$ 和 GRU中的 $h_{t-1}$ 的系数尽量接近于1。在LSTM中,我们所做的就是尽量使forget gate的值为1。为了做到这一点,我们可以将计算forget gate的bias初始化为1或者更大(我们无法对weight做一个好的初始化,因为我们无法知道怎样初始化weight才能让forget gate接近于1.但是调整bias就很直接)。对于GRU我们可以对于相应的bias做同样的初始化,但是不同文章中所用的GRU公式好多都是不同的,具体的情况应该看是什么公式。对于上面的公式我们就应该尽量将计算 $z_t$ 的bias初始化为-1.
其他的tips,我就不一一说了,具体可以看下这个博客。但是初始话bias这个问题,感觉特别重要,很多文章都有提到,所以在这里特别提一下。下面我用pytorch的代码来展示一下怎样初始化对应的bias。
1 | import math |
首先下面这是一个关于RNN的类
1 | class TorchRNN(nn.Module): |
LSTM forget gate bias初始化
从pytorh LSTM的官方文档中我们可以看到LSTM的计算公式,相对于博客上面的公式,pytorch是将输入和上一个隐藏状态的映射weight分开来了。
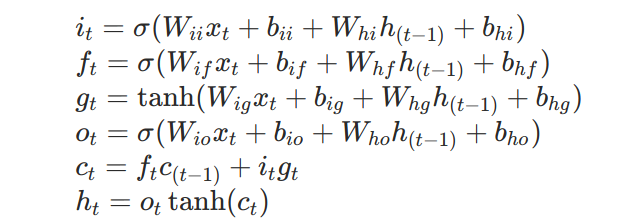
从下面的输出来看就分别是bias_ih和bias_hh
1 | model = TorchRNN() |
1 | torch.Size([4, 10, 512]) |
在上面我们的隐藏状态的维度是512,而两个bias的维度都是2048.相当于有4个512.这四个就是LSTM的四个gate。pytorch的官方文档也给出了这四个gate在bias中的顺序:

分别是input gate/forget gate/gate gate/output gate
那我们将对应与forget gate位置的bias改为1就可以了。
1 | print(model.rnn.bias_ih_l0.shape) |
1 | torch.Size([2048]) |
GRU 相应 bias初始化
从pytorch的GRU官方文档中可以看到,GRU的公式计算如下:
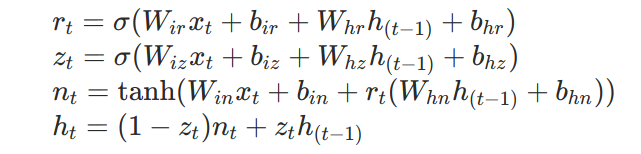
也即是说我们要将zt中对应的bias初始化为1
1 | model = TorchRNN(rnn="gru",) |
1 | torch.Size([4, 10, 512]) |
隐层的状态是512维,而这里的bias维度是1536维,对应的变换相对应的bias位置在pytorch文档中给出:

1 | print(model.rnn.bias_hh_l0.shape) |
1 | torch.Size([1536]) |