
自己在阅读这篇论文的时候,觉得这里面有很多有趣的观点。记录下来,希望能对自己以后的实验有所启发
前言
传统的说话人验证任务,是由很多分立的模块组成的。比如最经典的i-vector模型,会分为i-vector训练和plda打分模型训练。本片论文的作者认为这是很不好的,因为这样的做法并没有直接奔着说话人验证最终的目标去。比如UBM-ivector模型并不是直接优化说话人验证任务的。GMM-UBM模型对帧级别的建模也许会忽略掉上下文的信息。
基于以上原因,作者在本文提出了一个在训练阶段就直接去优化说话人验证任务中目标的模型框架。并在试验中对比了几种loss和模型框架的优劣性。
Baseline系统
本文所用的baseline系统是一个DNN加softmax的框架。作者认为baseline系统存在着以下的缺陷:
- DNN框架对于序列上下文的建模能力是有限的
- softmax的优化目标在于区分正确说话人和其他所有错误的说话人。作者认为这与说话人验证的最终评价指标不一致(说话人验证的时候是为了评判enroll和test是不是同一个人)。这种不一致可能会需要后续的各种启发式的得分norm之类的操作。
- softmax网络的计算复杂度,会随着说话人个数的增加而线性增加。所以说呢,softmax对于大数据并不是很友好。
- 此外,因为要对每个人进行分类,softmax对于每个人的训练数据是有要求的。太少的话就无法学到这些特定人的权值和偏置了。
总之,这一波分析感觉还是蛮有道理的嘛!!!
End-To-End Speaker Verification
既然上面的有这么多缺点,那就来解决喽。
作者文章中提出了一个end-to-end的框架。所谓的end-to-end就是直接去解决说话人验证的问题。模仿人验证的最后阶段。模型像说话人验证所接受的输入一致,即N个enroll utterance和一个test utterance,并在模型的最后直接输出这属不属于同一个人。
作者在文章中用了两种特征提取网络,一个是帧扩展输入的DNN,一个是lstm。
作者在介绍这部分的时候提到了很重要的一点,就是说训练的时候输入的enroll utterance的数量应该尽量和测试的时候一致。因为往往来说,训练集中每个人对应的utterance是很多的,而我们在真正进行enroll 的时候,只会有几个utterance。作者在后面的实验中也证实了这种数据量一致性是多么的重要。
Experiment
Frame-Level vs. Utterance-Level Representation
作者首先做了一个帧级别表达和utt级别表达的优劣:

这里两个DNN的差别是这样的。上面的DNN接收帧级别的输入,下面的是做了帧扩展。
Softmax vs. End-to-End Loss
两种loss的结果对比如下:
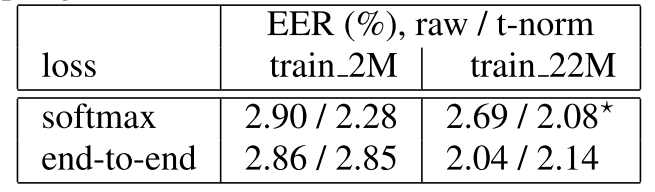
train_2M是一个小规模的数据集,train_22M是一个更大规模的数据集。
实验结论:
- 由于softmax的优化准则和说话人验证不一致,后期的score norm很重要
- 而end-to-end的loss在训练的过程就学习了一个全局阈值,后期的score norm几乎没有作用。
而且作者发现,在train_2M数据集上如果用softmax模型去初始化end-to-end模型的话,会得到更好的结果。但是在更大的数据集train_22M上这种现象就没有了。
关于在训练的时候,应该用多少enroll的utterance去估计说话人的模型,作者也做了一个实验。结果如下:
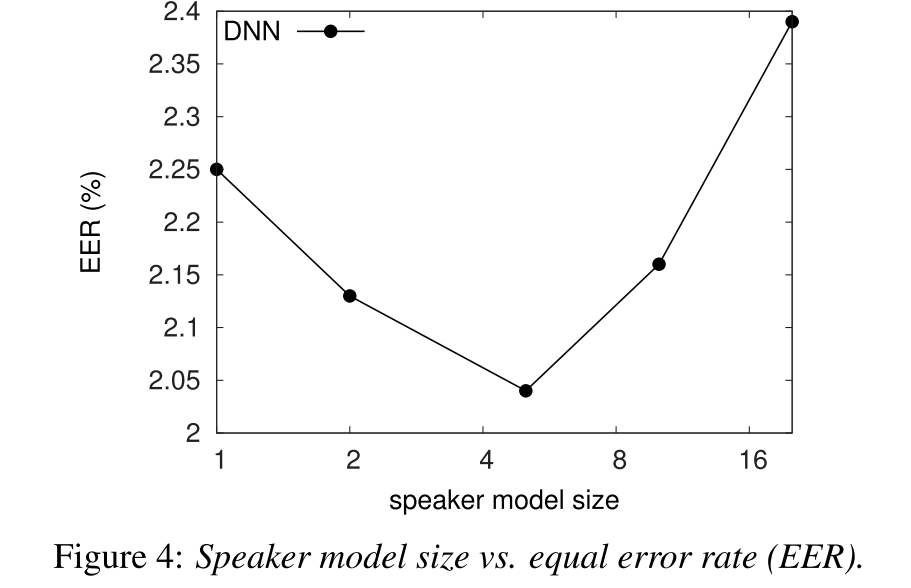
也就是在训练的时候,enroll的utterance个数为5为最佳,测试的时候enroll的平均utterance个数是6,可以看出当两者一直的时候是会有很大的提升的。
