
在自己看的众多说话人识别的论文中,不同的研究者为了达到intra-speaker距离最小化和inter-speaker距离最大化提出了众多的loss。虽然自己也无法记全都有哪些,但在这里先记起来,以后看到新的再做更新。
Softmax-cross_entropy Loss
这个loss的公式和种种就不在这里多说了,作为分类任务的经典loss,softmax是必不可少的。接下来主要分析一下这个loss用于说话人识别end-to-end系统中作为loss的优点和缺点。
优点
优点的话就是简单,完全不用自己动手去写代码,基本上所有的框架都有现成的函数供使用者使用。
缺点
- 扩展性不好。也就是说,如果我有两个说话人,我得搭建一个分类两个说话人的网络,如果有三个说话人,这个时候我就得换另外一个网络。这是很麻烦的一件事。当然可以只换最后一层。
- 网络大小随着说话人个数的增加线性增加。很明显,最后网络的参数数量是会加上最后一层的参数个数乘以分类的说话人个数。有几百个几千个说话人确实都不算什么。但有的数据集就是会有几十万个说话人,只是最后一层的映射估计就要有几百万甚至几千万几亿的参数,这个问题是很大的。但是大的数据集对于模型的好处大家都是知道的,所以这个问题必须得到解决。
Triplet Loss
这个loss最初是在CV的一篇论文中被提到的,为了计算这个loss,每次训练我们会sample一个三元组$(x^a_i,x^p_i,x^n_i)$ 分别是anchor,positive,和negative样本。positive样本和anchor样本属于同一个类别,而negative样本和anchor样本属于不同的类别。
首先我们会通过一个网络得到这三个样本的embedding:$(f(x^a_i),f(x^p_i),f(x^n_i))$, 而且我们希望经过训练之后positive样本能够离anchor更近,negative样本会离anchor样本更远。
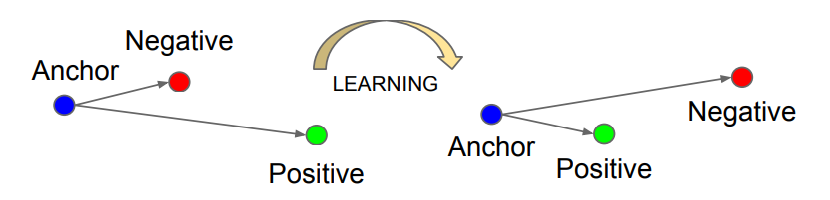
通过数学的表达是就是positive和anchor的距离在加上一个margin alpha之后小于negative和anchor的距离:
论文将Loss定义为:
优点
同时减小intra class距离和增大inter class距离
缺点
对于采样策略敏感,需要花功夫制定恰当的采样策略
Prototypical Network Loss
所谓的prototypical loss, 就是centroid loss的意思。论文链接
其实这个东西是和triplet loss差不多的,只是把triplet loss里面的anchor换成了几个embedding的center。
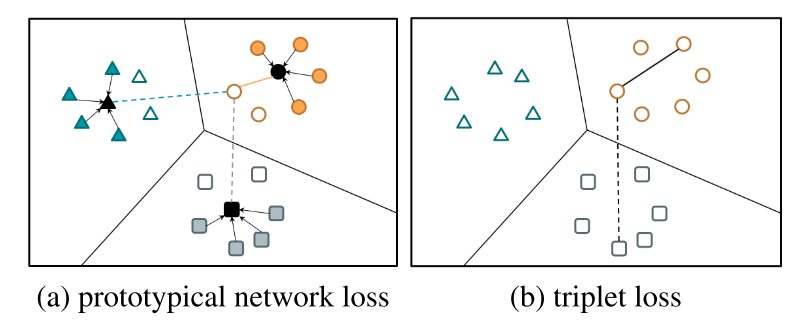
在这里作者提出了support set $S=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}_{i=1}^{N}$和query set的概念,两个set里面具有同样个数的说话人,support set用于产生embedding的center。 公式$\ref{centroid}$表示的就是每个embedding prototype(centroid)的产生方式。
最后的loss计算如下
其实这个loss和下面介绍的GE2E是很相似的,只是在GE2E里面,support set和query set是同一个set,而在这里是两个。
优点
可以说是对triplet loss的一个改进吧
缺点:
采样复杂
Tuple Loss
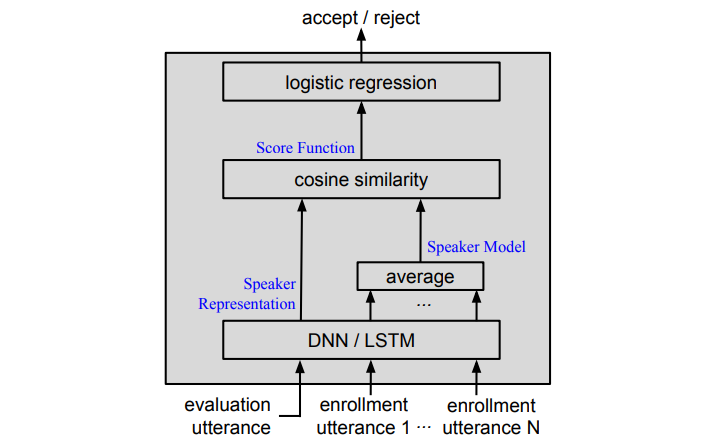
Tuple Loss是在谷歌这篇论文中用到的。Tuple loss的提出是为了模拟说话人验证的过程,说话人验证的过程是这样的,我们通过N个enroll的utterance训练一个说话人的模型,然后来了一个test utterance,我们通过训练好的这个模型对test utterance进行打分,然后通过一个得分的阈值来判断这个test和几个enroll的utterance是不是属于同一个说话人。
Tuple loss的做法是这样的,对于一次训练样本,我们sample一个tuple: $(x_{jl},(x_{j,i_1},…,x_{j,i_P}))$。脚注第一个字母是k的代表test utterance,脚注第一个字母是j的代表enroll utterance,这里我们共有P个enroll utterance。如果 $k=j$ 那么我们就称这个tuple为positive tuple,否则为negative tuple。
在训练的时候,我们将所有的utterance都输入到同一个网络得到,embedding:
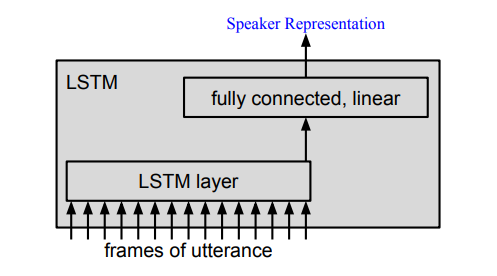
然后所有的enroll embedding经过平均就可以得到,我们所需要的speaker model :
然后用这个model与test embedding做一个余弦距离就可以做到对test utterance的打分:
最后通过一个逻辑回归完成二分类:
将Loss定义为:
$δ(j, k)= 1$ if j=k ,否则为0
优点
tuple loss优化的目标就是我们最后说话人验证的最终目标,是很直接的,所以这样我们就不用去设计中间的像LDA和PLDA这样的细节,所有的中间过程交给模型自己去优化就好了。
缺点
为了构建这样的tuple,很明显sample的策略异常重要,正负tuple的均衡,不同说话人数据之间的均衡,sample策略的设计好坏将会影响最终的性能。
GENERALIZED END-TO-END LOSS
这个loss可以说是上面提到的tuple loss的升级版本,也是goole的一篇论文中的提到的。是通过对tuple loss做了一些改进之后的版本。
我们先把论文中的一个主要流程图呈上来:
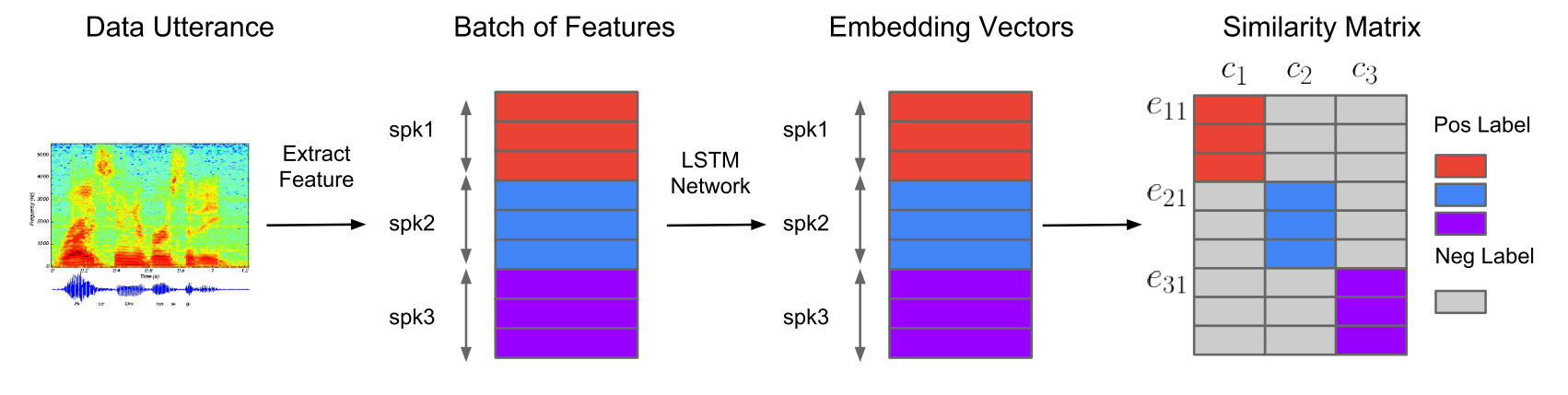
相对于tuple loss中的tuple sample,在GE2E的一个batch中,我们会采样N个speaker,每个speaker有M个utterance,就如上图中的第二个小图。
然后经过一个神经网络,每个utterance都会得到其对应的embedding。所以会共得到NxM个embedding。每个embedding都是经过L2 norm的。
同样的我们可以求得每个speaker M个utterance对应embedding的center。
现在我们有NxM个embedding和N个center。然后这NxM个embedding分别和这N个center做余弦距离,就可以得到一个(NxM)x N 的得分矩阵,也就是上图的第四个子图。彩色的部分代表utterance embedding与同一个说话人center之间的得分,我们会希望这个得分会比同一行中其他得分要高。
所以这个loss就可以用softmax进行定义了,对于上图中的第四个子图的每一行我们都可以将它看为是一个N分类问题的输出(当然论文中还提出了其他的定义方式,我就在这里就不介绍了)。
优点
很明显,GE2E的一个batch对于数据的学习就相当于tuple loss中(NxM)x N 个tuple,而且每个speaker的center计算可以被其他speaker利用,也减少了计算。
缺点
目前还没有特别直观上的缺点,只是自己跑代码的结果没有x-vector的效果好。