损失函数作为优化一个神经网络的目标,对于神经网络最后的性能影响重大。Softmax+crossentropy作为一个分类的损失函数受到大家广泛的使用。本文将对于softmax做一个推导,并对很多论文中对softmax所做的改进做一个总结。
Softmax+CrossEntropy损失函数
损失函数的定义
softmax交叉熵损失函数主要是针对多类的分类任务使用。假设任务中的类别数是 $C$ 。为了使用softmax交叉熵损失函数,首先需要将输入转为一个 $C$ 维的向量,这里用 $x_i ,(i \in [1,C])$ 来表示向量中每个位置的值。
然后,对这个$C$维向量中的所有值做softmax运算,以将每个值转为一种可以作为某种具有概率意义的值,计算之后的值记为 $z_i ,(i \in [1,C]) $ ,这样所有的$z_i$之和便是1,便可以用来表示输入样本输入每个类的概率值:
最后对 $z_i$ 做negtive log likelihood和crossEntropy运算,最后的损失函数被定义为:
这里的 $y_i$ 输入样本的类标签,如果输入样本输入类 $i$ . 则 $y_i = 1$ , $y_j =0,(j \neq i)$ .
反向求导
为了进行反向传播,我们需要求得 $\cfrac{\partial L}{\partial x_i}$ 的值,假设输入样本的类标签是 $t,t \in [1,C]$ ,为了计算偏导数,需要分为两种情况:
当 $ i = s$ 时:
当 $i \neq s$ 时:
将两种情况统一为一种情况:
Large Margin Cosine Loss
Large Margin Cosine Loss是论文CosFace中提出的一种softmax的改进方式,以下简记这个损失函数为LMCL。为了帮助理解,下面的符号将与论文中保持一致,可能会与上面softmax+crossEntropy部分稍有不同。
Motivation
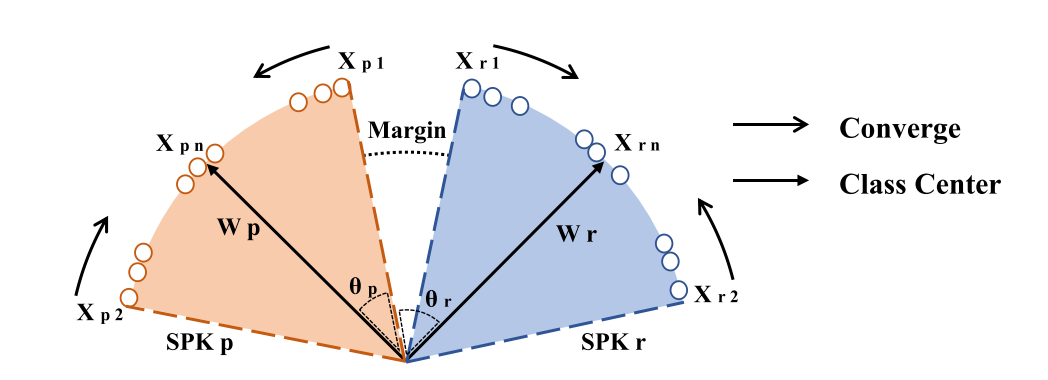
由于论文任务是人脸的识别和验证,所以任务的目的就是训练一种可以代表某个人脸特征,而且要尽量使得类内方差更小,类间方差更大。作者认为原始的softmax交叉熵损失函数的区分性能力不够强,因为原始的softmax交叉熵只是为了在训练集上优化每个样本的分类结果,不同类之间的距离(特征的距离)可能并没有通过训练变得很大,这样的话,如果测试集的数据和训练集稍有不同,或对数据做稍稍的扰动,一个类的数据就可能被分类为另一个类。
除此之外,softmax交叉熵优化的目标和测试的时候策略也稍有不同。如果我们将神经网络所提取的特征记为 $x$ ,假设向量 $x$ 的维度是 $F$. 网络所要进行的分类个数是 $C$ 。为了进行softmax交叉熵的计算,还需要一个维度为 $F \times C$ 的矩阵 $W$将向量 $x$ 映射为 $f$. 这里 $f_j = W^T_jx = ||W_j|| \, ||x||cos \theta _j$ .而在测试的时候,往往会只求两个特征向量之间的cosine距离来判断两个向量之间的相似性,也就是说测试的时候只将 $cos \theta$ 作为了评判标准。而在训练的过程中,最后损失函数的优化可能是通过对 $||W||$ 和 $||x||$ 的调整实现的。
实现策略
为了对以上两个缺陷进行改进,论文分别通过对损失函数加margin和对 $W$ 、$x$进行长度的normlize来实现。对损失函数加margin可以使得不同的类之间的距离更大,增加模型的鲁棒性,对$W$ 、$x$进行长度归一化可以将损失函数的优化目标聚焦到 $cos \theta$ 上,按照论文中所说的就是去除了radial variation,即去除了$W$ 、$x$的模长对结果的影响。最后的改进过的损失函数被定义为:
反向求导
设:
与softmax交叉熵损失函数求导时一样仍需要两种情况:
- 当 $ i = y_i $ 时:
当 $ i \neq y_i $ 时:
将两种情况统一为一种情况:
如论文中所说s是一个比较大的数,因此s会使得梯度变得更大,同时m的出现也会使得梯度变得更大,因此从公式推导来看,似乎在softmax交叉熵已经将梯度减小的一定程度已无法更新的时候,这个loss的梯度还会使得模型更新。
BOUNDARY DISCRIMINATIVE LARGE MARGIN COSINE LOSS
这个idea是在论文BOUNDARY DISCRIMINATIVE LARGE MARGIN COSINE LOSS FOR TEXT-INDEPENDENT SPEAKER VERIFICATION提出的,相对于普通的LMCL,BD-LMCL对于一个batch里要加margin的sample做一个选择,作者认为如果某个样本已经离类中心很近了,最后在loss里的贡献就不是很大,就不用加margin了,而是要对那些位于边界上的样本加margin惩罚是指里类中心更近。