
最近读了Goodfellow最初的那篇生成对抗网络的论文。在这里对论文中比较重要的部分记录一下。论文中还有好多自己不同的概念,希望后面自己还可以回来再加以补充。
背景
深度模型大体可以分为两种,一种是discriminative model,用于将输入的高维数据进行分类。深度神经网络已经可以在这方面做得非常好了。另一种是generative model,即生成模型,先不考虑深度神经网络,在对数据的分布进行建模的时候往往是通过最大似然来实现的。但由于在使用深度模型进行近似一些最大似然概率的计算的时候仍有很大的难度,所以深度神经网络在generative model模型方面仍做得不是很好。
作者提出的Generative Adversarial Nets(生成对抗网络)便是为了解决无法很好地用深度神经网络构建生成模型的问题。首先,作者解决的问题仍然是generative model的问题,而这里的adversarial(对抗)是解决这一问题的方法。
具体实现方式
具体的实现方式和题目描述的是一样的,即对抗。在整个生成对抗网络中,会大体分为两部分,分别是Generator(G)和Discriminator(D),而所谓的对抗就是这两者之间的对抗。这个对抗可以比喻为一个货币造假团队和警察之间的对抗。G就是货币造假团队,他们希望他们生产的假币可以欺骗警察,D就是警察,他们会竭力区分假币和真币。于是G和D就在不断地对抗之中提升自己的能力,直到G制造的假币和真币一模一样这场游戏便结束了。
而在generative model的学习中,我们最终希望的是能够学习到真实数据的分布。在这里G的作用便是学习真实数据的分布,然后通过学到的分布去产生假的数据。而D的作用,就是为了鉴别输入的数据是真实数据还是通过G产生的假数据。两者之间的对抗会使得G能够学到真实数据的分布。
而具体的操作中,G所学习的并不是某种分布(分布这种东西到底怎样用神经网络来表示,还真是一个问题),而是一种关于分布的映射关系。是这样的,通过数学知识可知(自行google),均匀分布(当然也不一定是均匀分布)是可以映射为任意分布的。也就是说,如果我们先用计算机产生均匀分布,然后便可以用G将均匀分布映射为真实数据的分布,这个时候也就相当于G学到了真实的分布。
优化目标
与论文一致,用$p_z(z)$来表示G要进行映射的分布,用$p_g$来表示映射之后的分布,这种映射可以表示为$G(z;\theta_g)$,$\theta_g$便是G要学习的关于映射的参数。假设真实的数据分布为$p_{data}$。对于任意输入$x$ , $D(x;\theta_d)$将会输出这输入$x$来自数据的真实分布的概率。最终优化的公式定义如下:
D希望能够最大化上面的式子,即能够正确的分类真实数据和生成的数据。而G则希望最小化上面式子中右边的部分,即G的优化使得D不再能更好地区分合成的数据。
一个简单示例的图形化解释
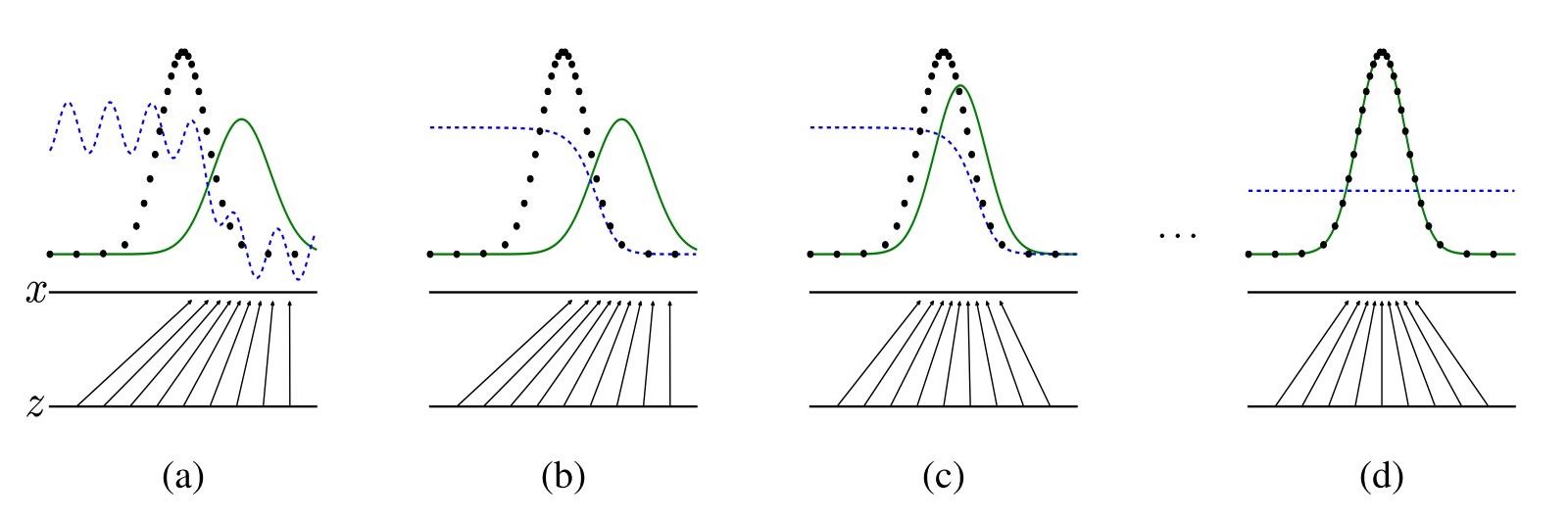
图中的黑色点线代表的是真实分布,绿色线是G生成的分布。蓝色线是D预测的关于真实数据的概率。z代表的是G输入的均匀分布,x是通过G映射之后的分布。
(a) 图可以代表一个接近于收敛的状态。(b) 中通过对D的更新,可以得到对于当前$p_g$下D的最优解,即$D^*(x)=\frac{p_{data}(x)}{p_{data}(x)+p_{g}(x)}$(论文中有证明)。(c) 更新G,G产生的分布越来越接近于真实分布。 (d) 训练结束,G产生的分布于真实分布一致。
更新过程
在实际的训练过程中,对于G和D是交替进行更新的,一般会先通过K轮的D的学习,使得D到达一个比较不错的分类状态,然后在对G进行一轮的更新。因为G的更新需要D进行梯度回传作为指导,没有一个好的D,便无法指导G进行正确的更新。
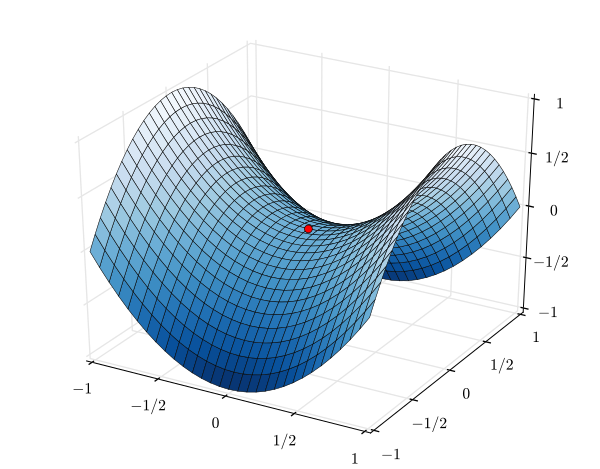
在更新的过程中,D不断地最大化优化目标,G不断最小化优化目标。正如下图的马鞍形状,可以理解为D不断地在y方向进行更新使得x固定的情况下z的值最大。G不断在x方向进行更新,使得y固定的情况下,z最小。最后的更新结果就是到达了图中的红色点,即鞍点。
优缺点:
- 缺点
- 没有明确的关于$p_g(x)$表达式。
- D和G必须实现同步更新,因此很难训练。
- 优点
- 不在需要马尔科夫链
- 只需要反向传播算法更新梯度就可以了