
Resnet可以说是深度学习跨时代之作,也是何凯明巨神被cited最多的一篇论文,今日才得以膜拜,惭愧惭愧。
Resnet的motivation
这篇论文的全称是Deep Residual Learning for Image Recognition,中文翻译就是深度残差学习。之前自己道听途说了解过resnet,但没有看过原始论文。在自己最初的认识中,以为这个论文的motivation是为了解决深度神经网络的梯度消失,看了论文之后才发现这个idea不是这么出来的。
在之前的很多研究中已经发现,简单的加深网络,并不一定会对实验最后的结果有什么帮助,而且深到一定程度反而会使得模型变差,而且这并不是由于过拟合造成的。
作者认为存在一种构造更加深的神经网络的策略,首先我们有一个浅层的神经网络,然后在这个浅层神经网络的基础上加一些层,就可以构造更深的网络。而且限定这些多加的层的功能,让这些层只具有copy前一层的作用,那么构造的更深的网络的性能就不会比原始的浅层网络差。但实验发现,我们现在的技术还无法做到去优化这个更深的网络,使得更深的网络的性能比前面的构造策略产生的网络还要好。
作者的想法是,如果一个比较理想的特征mapping是$H(x)$,但又担心这个mapping无法做到copy的目的,作者直接将$H(x)$拆成了两部分,$H(x) = F(x) + x$. 网络的参数用于拟合$F(x)$,被称为是residual部分,然后一个shortcut的连接直接实现x的copy,如下图。
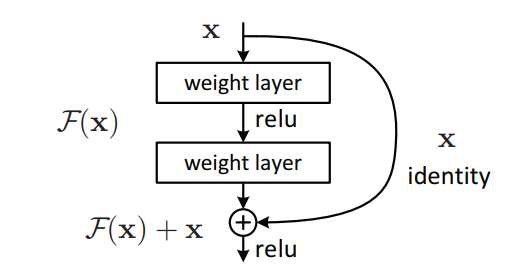
如果copy的做法是最优的,那么就让residual部分输出零就可以了。而且从理论上讲,让residual输出零也要比拟合一个copy功能的mapping更加的容易。
Resnet结构
对于shortcut $x$ 的一些处理
因为$H(x)=F(x)+x$ ,所以$F(x)$要和$x$有着同样的维度,但由于网络结构的问题,同样的维度并不一定能够保证。面对$F(x)$和$x$维度不一致的情况,一般有三种解决方案:
- 将方程改为,$H(x)=F(x)+Wx$ ,对x做一个矩阵映射,将x的维度映射为与$F(x)$一致。
- 假如只是dimension增加了,比如,在进行CNN的时候,channel的个数增加了,可用zero-padding去补多余的dimension
- 假如只是dimension增加了,可以用$H(x)=F(x)+Wx$去的到多余的dimension,与$x$一致的dimension仍然用copy
Resnet block的一些形式
在论文中,作者提出了两种小的resnet block,用这些小的block可以堆叠形成最终的resnet。这两种block分别是下图左边和右边的图示。
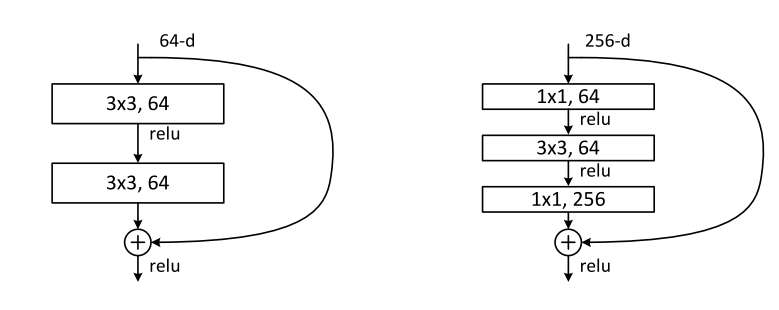
3x3的卷积核可以通过padding=1,stride=1的设置从而实现映射之后维度不发生变化。需要注意的细节是,relu在求和之后。
一些论文中有用的结论
- 单纯的加深网络并不一定能获得更好的模型性能,而且这种性能的下降并不是由于过拟合造成的。
- 在作者的工作之前,就有人做过gating(对于x会加一个权重,这个权重和输入有关)的highway模型,但这种模型在网络变身的时候表现得并不是很好。
- resnet的block应该有两到三层,实验证明,一层,并没有什么用,更深的话也可以。
- 作者发现,更加深的网络使用的BN之后可以解决梯度消失的问题,但是即使这样,更深网路的性能也会变差。
- 而且当层数比较少的时候,虽然residule不能带来准确率上的提升,但是在模型训练的初始阶段,resudual网络收敛也更快。