
GAN自从被提出之后就受到了广泛的关注,GAN也被逐渐用于各种有趣的应用之中。虽然GAN的idea对研究者们有着巨大的吸引力,但是GAN的训练却不像普通DNN那样简单,generator和discriminator之间的平衡,训练过程中没有很好的指标度量训练效果成为了训练GAN的难点。WGAN的提出几乎完美解决了这两个问题。
参考文章:
Table of Contents
原始GAN存在的问题
要想知道原始GAN存在什么问题,我们先看一下GAN的优化目标。
作者在原始论文中提到,在真正优化G的时候 $log(1-D(G(z))$ 可能无法给G提供足够的梯度,于是可以通过maxmize $log(D(G(z))$ 的方式来更新G。而在WGAN的前序论文中,证明了这两种优化G的方式都是有一定问题的。
优化准则$log(1-D(G(z))$ 带来的梯度消失
在论文中,作者也给出了相关的证明,通过一步步优化公式$\ref{gan_target}$,最终的目标就是使得$p_{data}(x) = p_g(x)$ .
优化D
由$\cfrac{\partial Loss}{\partial D(x)} = 0$ 可以得到:
优化G
将公式$\ref{d_res}$ 中的结果,带入公式$\ref{gan_target}$ ,可以得到得到最优的D之后,优化G的目标
在此,介绍连个分布距离度量的指标:
- KL divergence: $KL(P_1||P_2) = \mathbb{E}_{x \sim P_1} log\cfrac{P_1}{P_2} \label{kl_div}\tag{4}$
- JS divergence: $JS(P_1||P_2)= \cfrac{1}{2}KL(P_1||\cfrac{P_1+P_2}{2})+\cfrac{1}{2}KL(P_2||\cfrac{P_1+P_2}{2}) \label{js_div}\tag{5}$
G的优化目标$\ref{g_loss}$可以通过形式的变换转为JS的的形式:
虽然我们将G的loss转为了某种距离,即JS,但是这种距离是有点问题的。看下面两张图,假设p就是真实分布,q是我们生成的分布。可以清晰的看出,KL和JS散度在q的均值为零的时候都为0。但是随着q远离p,KL和JS逐渐趋于定值,而且JS趋于定值的速度更快。既然趋于定值了,那么相应的梯度就是0了。
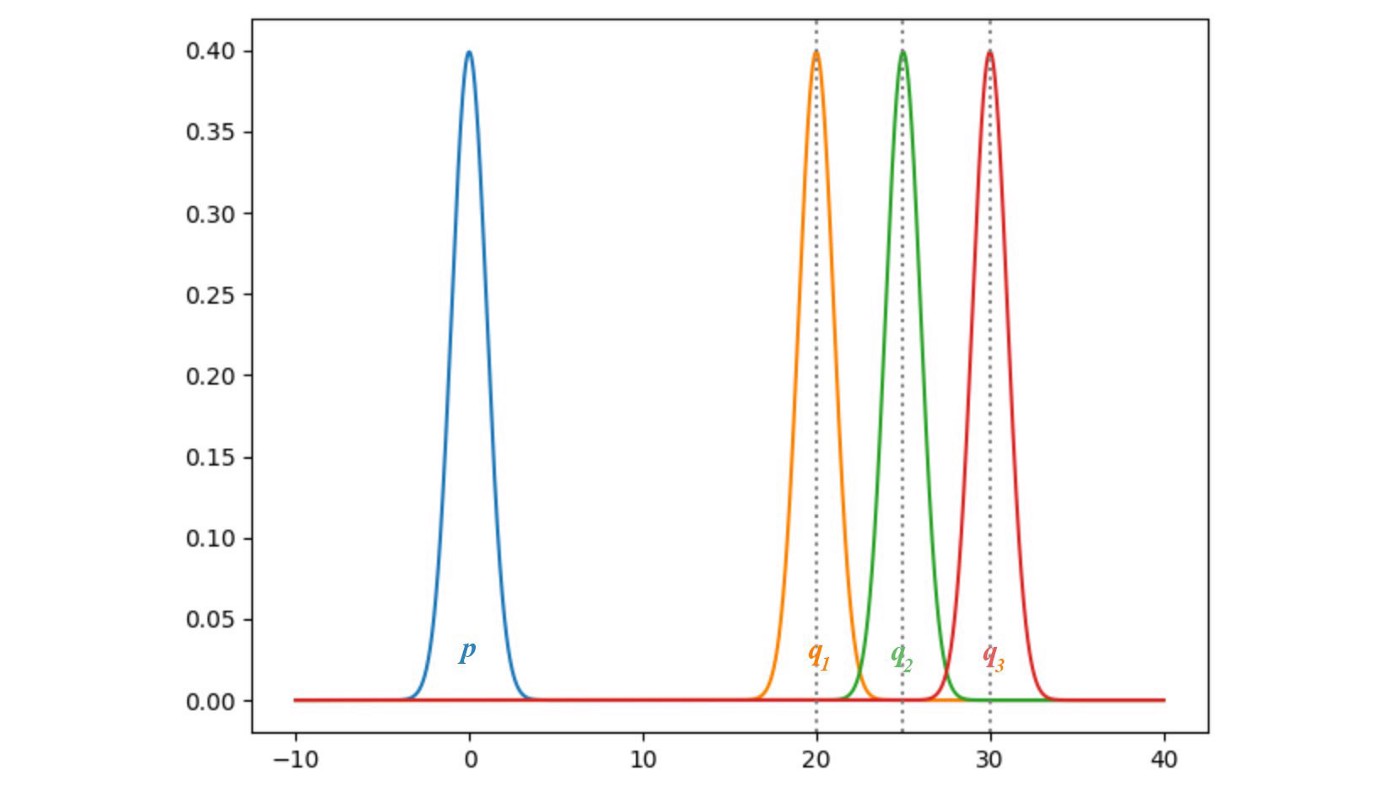
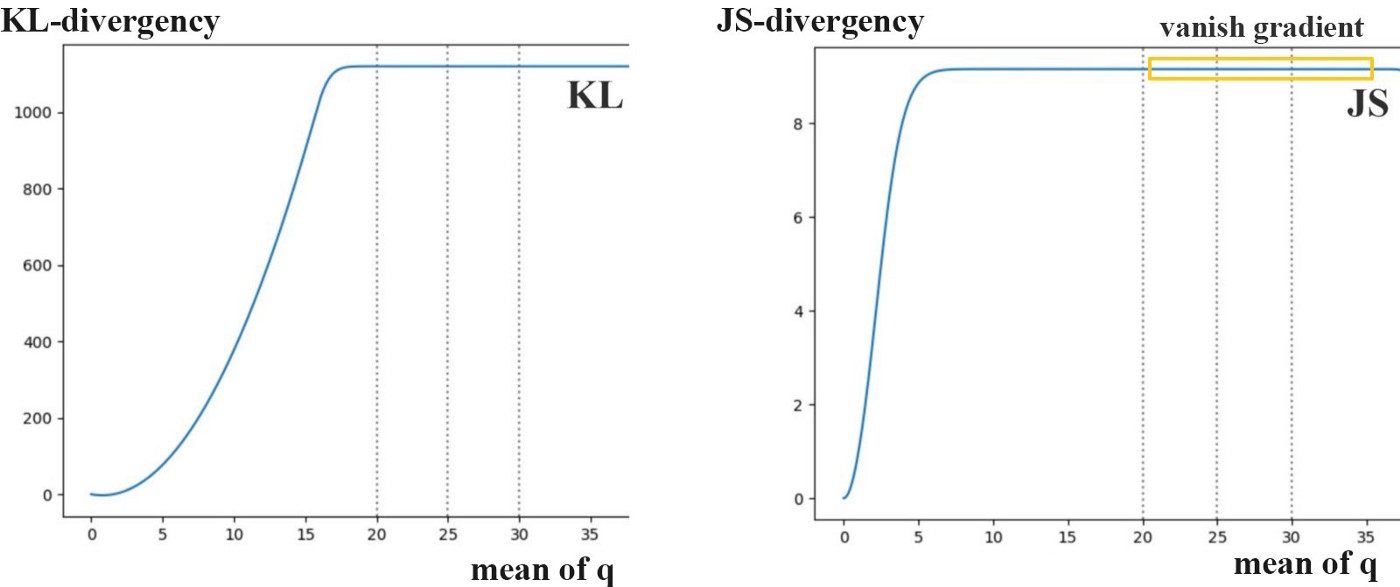
也就是说,两个分布越近,JS产生的梯度就越大。但是真实分布和生成的分布有一定重合的概率有多大呢?请看这篇知乎中关于高维空间的低维流形的介绍。结果就是,两个分布很可能是高维空间中的低维存在,两个低维物体在高维空间的交集仍是低维的,这个交集在高维空间的测度就基本为零(比如两个二维物体在三维空间的交集的体积怎么都是零)。
D在最优的时候,在优化G的时候就等同于优化JS散度,这样的话,我们就不能将D训练到比较好。但是,我们又不能将D训练到太差,太差的话,D就没法指导G进行更新了,更新G的时候梯度就不再准确。因此,怎样平衡每个stepG和D的训练程度是一个很令人头疼的问题。
WGAN的前序论文也通过实验验证了梯度消失的问题:
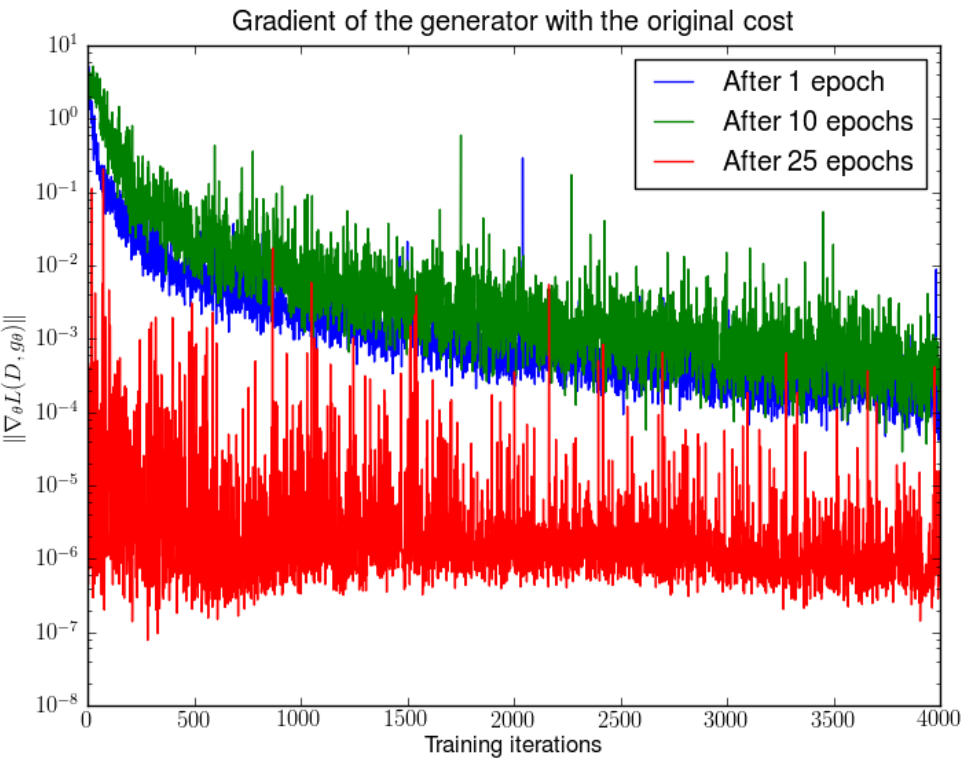
1
在分别训练了DCGAN 1,10,25个epoch之后,固定generator的参数,将discriminator随机初始化重新训练,generator梯度的变化。可以发现,随着discriminator的训练,generator的梯度会逐渐减小(指数减小)。
优化准则$-log(D(G(z))$ 带来的梯度不稳定和collapse mode
这时G的损失函数为$\mathbb{E}_{x \sim P_{g}}[-\log D(x)]$
在前一部分我们知道,在判别器最优的情况下($D(x) = D^*(x)$):
通过对KL散度的形式变换可以得到:
由公式$\ref{equation_6}$和$\ref{equation_7}$可以得到:
去掉上面公式中不含G的项,最后的优化目标变为:
这个损失函数一方面想要最小化KL,一方面又想最大化JS, 在直观上难以理解。
此外,由于KL 散度非对称性,对于$K L\left(P_{g} | P_{data}\right)$
- $当 \ P_{data}(x) \rightarrow 0 \ 而 \ P_{g}(x) \rightarrow 1 \ 时,K L\left(P_{g} | P_{data}\right) \rightarrow +\infty$
- $当 \ P_{data}(x) \rightarrow 1 \ 而 \ P_{g}(x) \rightarrow 0 \ 时,K L\left(P_{g} | P_{data}\right) \rightarrow 0$
上面的两种情况对应了两种错误,第一种是生成了错误的样本,第二种是有些应该生成的样本没有生成,可以看出,根据第二种情况,G可以只去拟合真实分布的部分分布而不会受到惩罚,而生成错误的样本则会受到巨大的惩罚。如果G按照第二种情况的指示去生成样本就很可能导致collapse mode。
同样的,WGAN的前序论文也通过实验验证了梯度不稳定的问题:
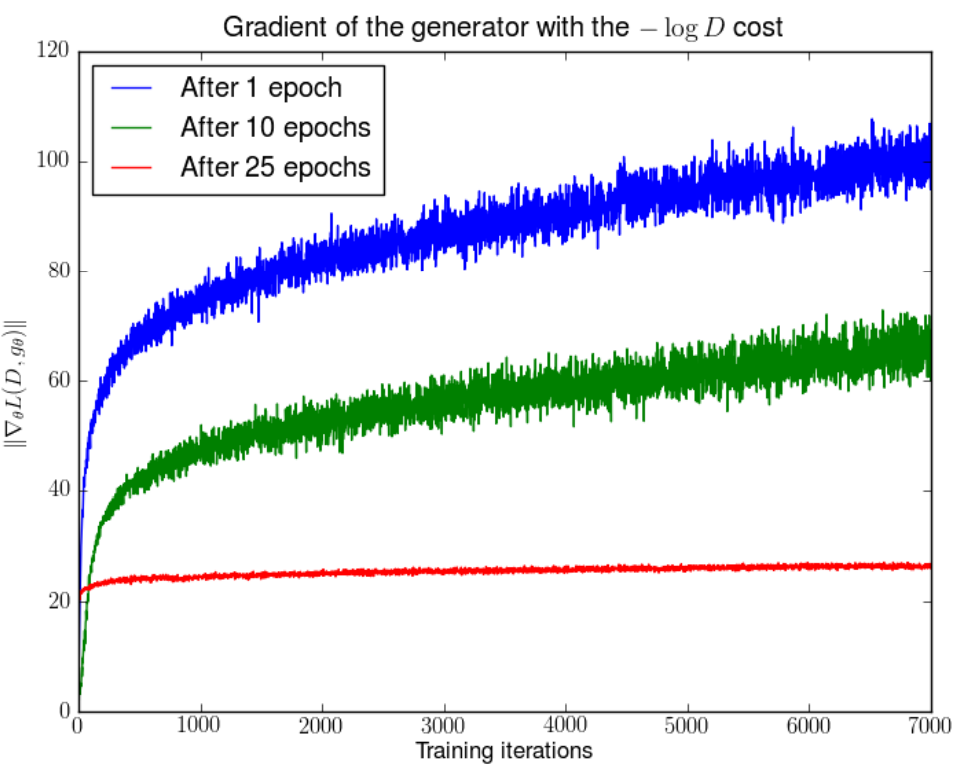
1 | 在分别训练了DCGAN 1,10,25个epoch之后,固定generator的参数,将discriminator随机初始化重新训练,generator梯度的变化。可以发现,随着discriminator的训练,generator的梯度会逐渐增大(指数增大)。 |
WGAN介绍
新的距离定义,Wasserstein距离
从上文可以看出,不管是JS还是KL距离,两者都有某种不连续性,也就是说当两个分布距离超过一定程度的时候,两者都将距离认为是定值。这对于优化两个分布是非常不利的,WGAN定义的距离则更加的合理。
WGAN使用的距离Wasserstein距离又被称为是Earth-Mover (EM) distance,中文称为搬土距离。可以进行这样简单的理解,A省有三个市A1、A2、A3,这三个市分别有5,2,3吨土,B省有四个市,B1、B2、B3、B4,分别需要1,6,2,1吨土,我们希望A省通过一定的策略将A省拥有的土送往B省,并希望A省制定一个比较好的方案,让A省运输过程消耗最少。
公式如下:
可能,有点复杂。其实和搬土是一样的,只不过我们将每个省需要和拥有土量的分布换为了连续的分布$\mathbb{P}_{r}$ 和 $\mathbb{P}_{g}$ 。将某个省某市将土运到另一个省某市这种情况的出现换为了两个分布某个值同时出现,即联合分布。运土的策略有很多,两个边缘分布的联合概率也有很多,在所有的联合概率中寻找使得方程$\ref{equation_10}$值最小的那个,代表的就是Earth-Mover (EM) distance。
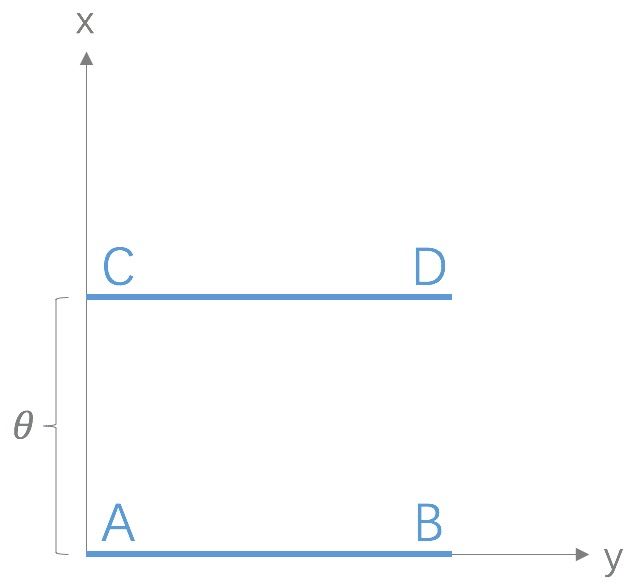
这个距离的度量相对于KL和JS到底好在哪里,我们可以假设这样一个分布:
P1在线段AB上均匀分布,P2在线段CD上均匀分布,CD的位置由$\theta$来决定,
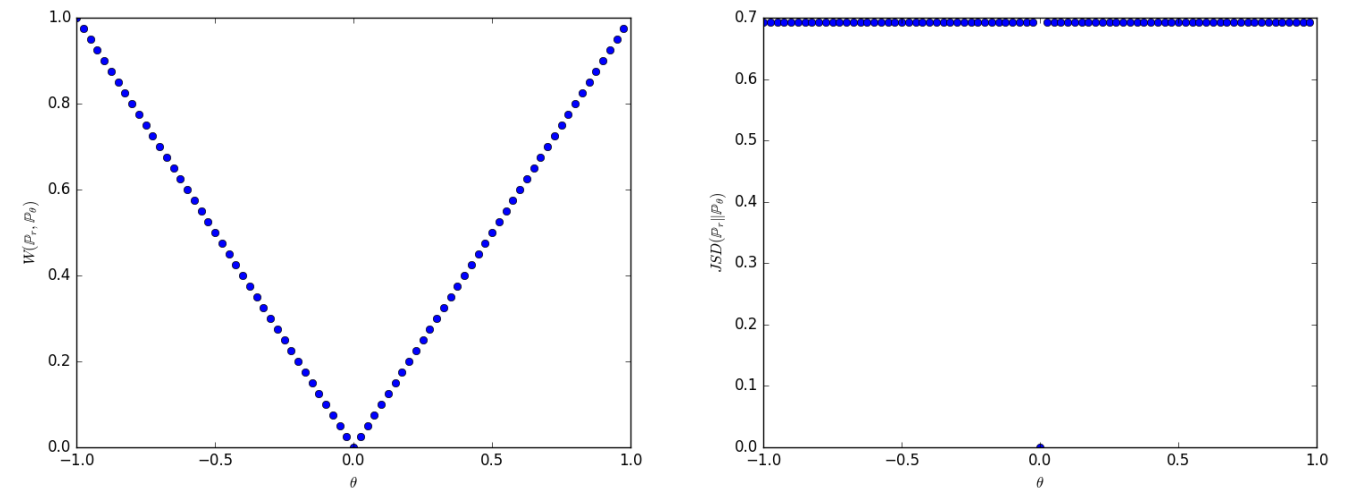
上图分别是,随着$\theta$的变化,W距离和JS距离的变化,可以看出W距离是连续变化的,而JS距离只在$\theta$为0的时候为0,在其他时候都是一个定值。也就是说W距离在这种情况下仍然可以为参数更新提供有用的梯度,而JS距离不行。
WGAN的具体实现
公式$\ref{equation_10}$的距离固然优美,但公式中的便利联合分布求下界的部分$\inf _{\gamma \in \Pi\left(\mathbb{P}_{r}, \mathbb{P}_{g}\right)}$却无法求解。作者为了更好的求解,讲公式$\ref{equation_10}$变换为了另一种形式:
公式$\ref{equation_11}$中$|f|_{L} \leq K$,是指函数f满足常数为K的Lipschitz限制,这要求对于定义域内的任意两个元素$x1$和$x2$满足:
也就是说,f的导数值有上界。这里W是要在所有的f中找到一个上界值。
遍历公式$\ref{equation_10}$中的联合分布是一个很难的事,但是遍历公式$\ref{equation_11}$中的f却很容易通过神经网络实现,每个神经网络都可以看作是一个映射函数,遍历神经网络的参数就相当于遍历所有可能的f。为了找到公式$\ref{equation_11}$的上界,我们可以转换为下面的问题:
现在重要的问题是,我们遍历参数w的时候不应是随便遍历的,在遍历的时候f应满足Lipschitz连续条件,因为只有这个时候公式$\ref{equation_11}$的上界才是W距离。
那么如何实现Lipschitz限制:
Weight Clip(权重剪切)
作者在第一WGAN的论文中,介绍了通过梯度剪切的方式实现对f的Lipschitz限制的目的。也就是说,如果神经网路f的所有参数$w_i$都在某个范围$[-c,c]$内的话,那么f关于输入样本x的导数也会在某个范围里面,虽然我们无法确定导数的范围具体是多少,但是只要导数值是有上界的,目的也就达到了。
Gradient penalty(梯度惩罚)
weight clipping的问题
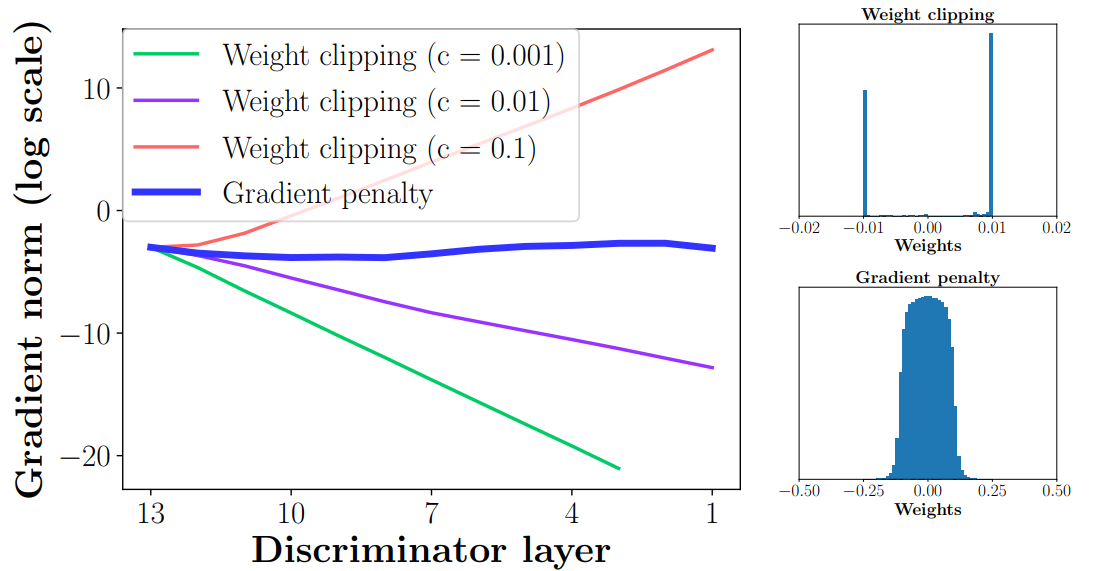
虽然权重剪切确实可以解决Lipschitz限制的问题,但是会有些问题,因为在优化D的时候是在weight clipping的限制下进行的,优化D的目的是为了最大化公式$\ref{equation_12}$,为了达到这个目的,函数可能会尽可能的将参数值推向参数范围的边界,也就是最大值或最小值。这样的话,就大大浪费了深度神经网络的拟合能力。而且如果网络参数都是范围边界值$c$或$-c$的话,$c$比较大的话梯度反传的时候会不断增大,很容易产生梯度爆炸的问题,$c$比较小怎会产生梯度消失的问题。作者也用实验验证了这两个问题:
1
注:左图是不同Weight clip权重情况下,梯度在反传过程中norm的变化。右图是weight clip和gradient penalty的参数的分布状况(图中weight clip的c设为了0.01)。
gradient penalty的具体形式
既然Lipschitz限制是对导数的,Weight clip对权重限制可以说是走了一个更加曲折的路,gradient penalty则是直接对梯度进行限制。作者这里是对f对于x的梯度的norm做了一个限制,作者希望梯度的norm能够小于一个常数K,这里我们就不妨设K为1. 与上文想法一样,在最大化公式$\ref{equation_12}$的时候,优化器会把f推向限制的边界,即f对x梯度的norm为1.(论文里也有一些证明),所以我们就不妨让梯度的norm为1:
但公式$\ref{equation_13}$的第三部分有个问题,这里是说f对所有的x都满足梯度norm为1。但是我们是不可能遍历一个高维空间的,作者使用了一个比较有效的trick,就是我们只对$P_r$、$P_g$以及两个分布之间的区域做限制就好了。也就是说我们取 $\hat{\boldsymbol{x}} \leftarrow \epsilon \boldsymbol{x}+(1-\epsilon) \tilde{\boldsymbol{x}},\ \epsilon \sim U[0,1]$ 。
WGAN的优势具体体现在哪里
- 相对于其他结构更加稳定,对D和G的结构没有特别苛刻的限制,不需要刻意的去平衡D和G的训练(不存在G的梯度消失和不稳定)。作者在论文的附录给出了在不同结构的D、G情况下,很多GAN模型都无法维持一致较好的性能,但是WGAN-GP一直都保持着稳定的性能。
- 训练过程中,Wasserstein距离距离的值可以作为模型训练的好坏的一个判断标准,Wasserstein距离值越小,说明生成的分布和真实分布越近。(但实际训练过程中,公式$\ref{equation_11}$ 应该是先上升后下降的,上升的过程是我们通过优化D使得公式$\ref{equation_11}$ 逐渐能够代表W距离,下降的过程是我们通过D的指导下优化G从而使得生成分布与真实分布越来越接近)