
ICASSP 2019已经过去很久了,论文都还没看,今天准备看起来了,主要是SPEAKER方面的吧,我会分几块去看,然后对19年的热点做一个总结吧。
Table of Contents
ICASSP 2019大家关于speaker的任务的研究重点
关于speaker的任务,需要研究的点是很多的,在本文中我将根据ICASSP的论文所研究的热点将论文分为几部分,并在下面分别做总结。
The Aggregation Of Frame Level Feature
众所周知,在目前的语音任务中,都是要通过信号的预处理将信号分帧,然后对每一帧提声学特征,最后输入到神经网络中的。由于声学信号的时序性质和每个声学信号时长的可变性,我们可能无法特定的去构造一个神经网络(LSTM当然是可以的),对于任何的长度的输入,都得到一个定长的表示。因此我们需要将frame-level的特征表示aggregation一下,得到一个定长的utterance-level的表示,下面将对几种aggregation的方式做一个介绍。
ICASSP 中出现的相关论文:
相关方法:
LSTM系
NetVLDA
这种方式主要是受检索相关技术的启发,在这种方法中,将为所有的frame-level学习K个类中心,然后用一个utterance中所有frame-level特征相对于类中的residual的加权和作为这个utterance的特征。
Average
就是对所有frame-level的特征进行average得到utterance-level的特征,当然average的时候可以通过attention的方法得到一个更好的结果。
Statistic Pooling
相对于average,所有frame-level的std特征将会和mean一起作为最后的utterance-level特征。
std也可以通过attention的方式得到一个更好的表达。
Optimize Objective
所谓的优化目标,指的就是不同形式的loss。具体请到Loss summary in Speaker recognition.
Invariant Embedding
这里所说的invariant embedding是指这个embedding应该相对于各种说话人无关的信息invariant。
- TRAINING MULTI-TASK ADVERSARIAL NETWORK FOR EXTRACTING NOISE-ROBUST SPEAKER EMBEDDING使用anti loss来提取noise-invariant的embedding。
- A ROBUST TEXT-INDEPENDENT SPEAKER VERIFICATION METHOD BASED ON SPEECH SEPARATION AND DEEP SPEAKER这个论文结合了speech separation(去除噪声获得干净的声音)和说话人分类的网路,并利用speech separation的中间特征作为已经去除噪声的干净特征与说话人分类网络的输入Fbank concat,从而实现网络对噪声的invariant,但是单从结果上看,这个网络好像只有在SNR<0的时候才有用。
Model structure
改变模型的结构去提取更加鲁棒的特征也是研究更好地说话人embedding的一个方向。
SEQ2SEQ ATTENTIONAL SIAMESE NEURAL NETWORKS FOR TEXT-DEPENDENT SPEAKER VERIFICATION
首先这篇文章也模拟了enroll和evalution的过程,也就是说在训练的过程中会对enroll segment和evaluation segment的距离作为最后训练的metric,只不过这篇文章提出了一种新的方式去计算两者之间的距离。
如下图,对于时间长度可能不一样的enroll和evaluation utterance,作者会通过attention的方式将evaluation的utterance align到和enroll一样长,然后将长度一样的feature concat之后咋average,最后score。
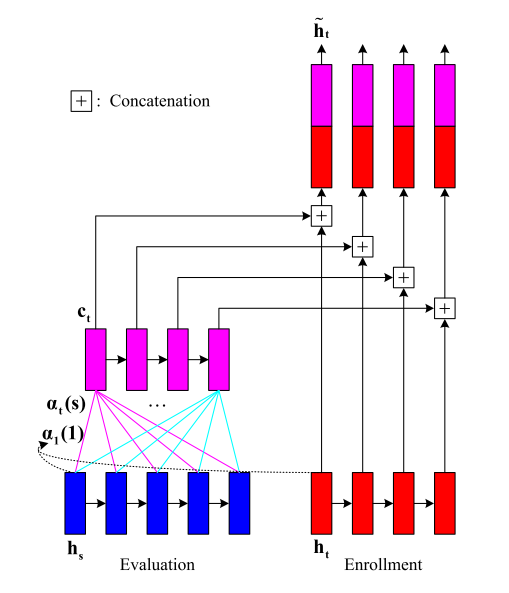
DEEP SPEAKER EMBEDDING LEARNING WITH MULTI-LEVEL POOLING FOR TEXT-INDEPENDENT SPEAKER VERIFICATION
这篇文章首先将TDNN和LSTM结合了起来,结合的目的主要是使用结合两种不同的statistic pooling的结果,做人认为TDNN更加着重提取local的信息,而LSTM可以建模时序的信息两个结合起来会更好,结果也得到了正式。
此外作者还提出了一个小的trick,就是说对embedding加norm减小embedding的数值范围会时候最后的性能更好。
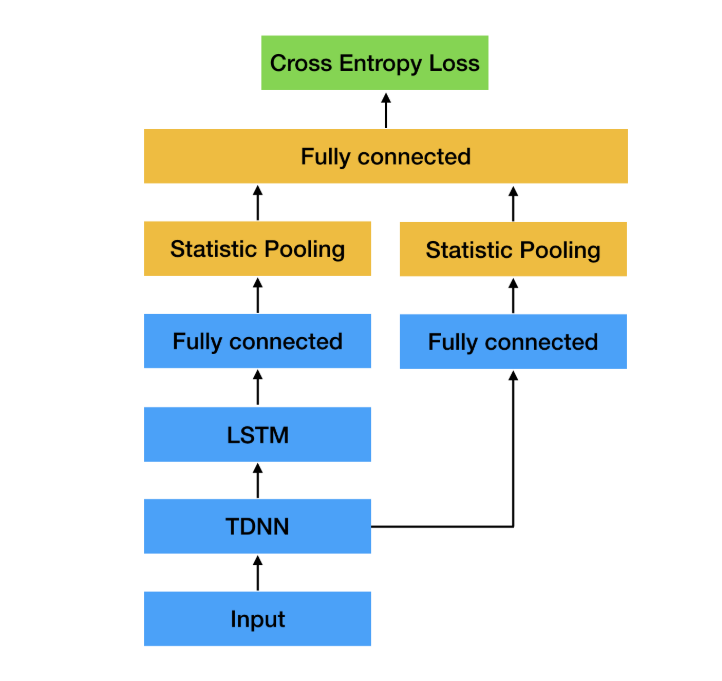
SPEAKER CHARACTERIZATION USING TDNN-LSTM BASED SPEAKER EMBEDDING
作者在这篇文章中,对x-vector结构进行了一些改动。将第二层和第三层TDNN去掉换成了LSTM,说是为了更好地建模时序的信息。当然结果上也取得了改进,但我觉得换LSTM的话,对于训练的速度影响会特别大吧。
而且其实我对于作者在论文中给的结果也很疑惑,作者分别使用了statistic pooling之后的两个线性层得到的结果作为embedding来测试最终的结果。x-vector在这两个层面上的结果差别是有的,但不是很大,但是作者提出的结构在这两个层面上差别是巨大的。
Information leak
一般来说训练embedding的任务是说话人分类的任务,但是在提取embedding的时候或吧说话人分类的参数扔掉,就是说训练中学到的信息不能被充分利用,这种现象被称之为information leak
GAUSSIAN-CONSTRAINED TRAINING FOR SPEAKER VERIFICATION
在这篇文章中,作者觉得可以直接用speaker-level的embedding来进行utterance-level 的说话人分类。在下面的公式中$v(x)$是speaker-level的,$f(s)$是utterance-level的。这样做确实可以解决information leak 的问题,但是在实际的操作中,需要定期的去更新$v(s)$这可能会使得训练很慢,而且会造成训练过程的波动。
然后作者的做法是,仍然保留分分类的参数,$\theta_s$代表对应于说话人s的那个参数向量。作者希望这个参数能够更加的靠近$v(s)$,于是加了下面的constrain。并认为这样做可以作为一种soft 的full-info training。
Embedding Constrain
为了使得backend打分可以有着更好的效果,很多论文中对embedding加了一些constaint。
GAUSSIAN-CONSTRAINED TRAINING FOR SPEAKER VERIFICATION
PLDA对于embedding有着gauss分布的假设,因此作者就对embedding做了gauss的constraint,在原始的x-vector上也取得了一定的改进。作者所加的constraint就是公式$\ref{gauss}$,作者认为这样做了之后,能够使得属于speaker s 的utterance-level的xvector $f(x_t)$服从高斯分布$N(\theta_s,\mathbf{I})$.